




Video Annotation
Video annotation for AI projects
Video annotation helps AI models to operate in fast moving, real-world environments. However, this essential process is also expensive and time-consuming. To annotate video human workers locate and label objects in every video frame. Managing this difficult task can be a significant distraction for AI company engineers and senior management. As a result many computer vision innovators choose to outsource their video annotation to professional services. Annotation providers ensure that AI projects receive exceptional video training data without the burden of management, training and quality control.
Bounding box annotation
![]()
This is the most common, fast, reliable and cost-effective annotation method.
Polygon annotation
![]()
This is what you need if you are dealing with irregular shapes and your project requires more precision than regular bounding box annotation.
Semantic segmentation
![]()
Do you need to group multiple objects of a single category as one entity? Then semantic segmentation might meet that need. Contact us to learn more, our specialists can help you to identify the right video annotation type for your project.
Skeletal annotation
![]()
Reveals body position and alignment. This technique is commonly used in sports analytics, fitness and security applications.
Key points annotation
![]()
Identify and mark key points of an object in videos, such as eyes, noses, lips, or even individual cells.
Lane annotation
![]()
This technique is used for annotating roads, pipelines and rails, this is one of the annotation types most commonly used by car manufacturers today.
Instance segmentation
![]()
We can easily detect instances of each category and identify individual objects within these categories. Categories like “vehicles” are split into “cars,” “motorcycles,” “buses,” and so on.
Custom annotation
![]()
If your project requires a specific combination of annotation types, or even a new annotation type, we can easily achieve that for you. Alternatively, our exceptional R&D team can evaluate your project and create a completely new video annotation type based on your specific requirements.
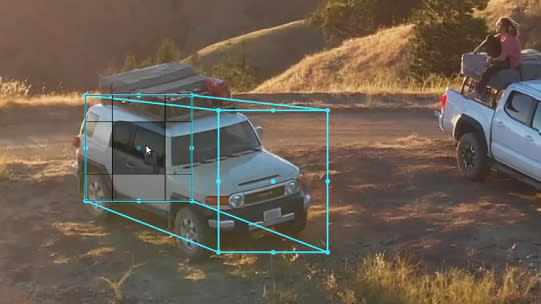
Cuboid annotation
![]()
Cuboids are a perfect solution for projects that require the exact dimensions of objects in a video to be accurately measured. In addition, you can use cuboids for tracking products, furniture layouts, or anything that requires specific 3D measurements.
Video annotation types
Video significantly increases the annotation workload by multiplying the amount of images that must be labeled in a dataset. Each frame of video must be as precisely
annotated as an individual image. This process can be sped up by making use of object interpolation techniques. Object interpolation algorithms track a labeled object
through multiple frames, allowing annotators to create video annotations much more efficiently.
The needs of AI developers determine how each frame of video training data should be labeled. Therefore, we use a variety of annotation types to achieve their desired results:
BOUNDING BOX ANNOTATION
ROTATED BOUNDING BOXES
CUBOID ANNOTATION
POLYGON ANNOTATION
SEMANTIC SEGMENTATION
SKELETAL ANNOTATION
KEY POINTS ANNOTATION
LANE ANNOTATION
INSTANCE SEGMENTATION
Bitmask ANNOTATION
CUSTOM ANNOTATION

This is the most common annotation type. Annotators use an annotation platform to drag boxes around objects in video frames.
Consequently, this technique is fast and easy to perform. However, it does not fully capture the shape of complex objects at the pixel level. AI models for autonomous vehicles often rely on video training data highlighted with bounding boxes. Labels created with this method help train computer vision models to identify objects and navigate in chaotic environments.

Sometimes traditional bounding boxes do not suit particular shapes. For example an axis-aligned bounding box may work well for an image of a person standing but might not fit well with somebody laying down.
Rotated bounding box annotation allows annotators to pivot boxes so that they accurately conform to a targeted part of a video.

Cuboid annotation adds more dimensions to training video datasets. Annotators create cube shapes by using a 2D box to locate one side of an object, then an additional box is used to identify the opposite side.
By linking both boxes together we can create a 3D cuboid in a 2D image. This allows more information about objects to be contained in training videos, including height, width, depth, and position.

If you want to precisely define the shape of an object it is necessary to use this annotation type. Annotators connect small lines around the pixel outline of target objects.
Polygon annotation allows each frame of video to be segmented more accurately. This annotation type is important for agricultural management, plant monitoring and livestock management AI systems.

Environmental perception is crucial for many AI use cases. For autonomous vehicles environmental perception means having an awareness of the road environment, including road markings, obstacle locations and vehicle velocities.
By assigning each pixel in an image to a particular class semantic segmentation for video data promotes this high level situational awareness. We can label target objects and their surrounding context using polygon annotation.

This annotation type is done by adding lines to human limbs in video frames. Annotators connect these lines at points of articulation, e.g. knees, shoulders.
There are a number of AI use cases that require machine learning models to interpret the movement of the human body. As a result, video data featuring skeletal annotation often trains sports analytics systems and home fitness products.

Video training data can be used to make facial recognition models for security or retail applications. Key point annotation is a vital part of creating these datasets.
This technique involves annotators marking key facial features, for example mouth, nose, eyes, as they appear in each frame of video.

This annotation type makes it possible to label linear and parallel structures in video frames.
Examples include: power lines, train lines or pipelines. Automated vehicles rely on line annotation because it allows models to recognise road markings and stay within them.
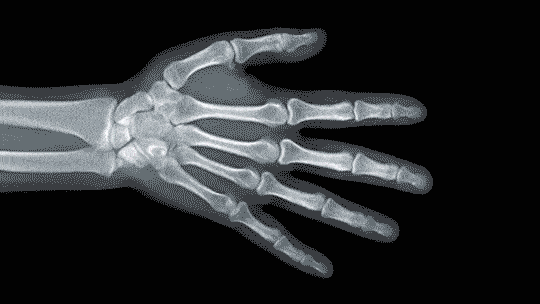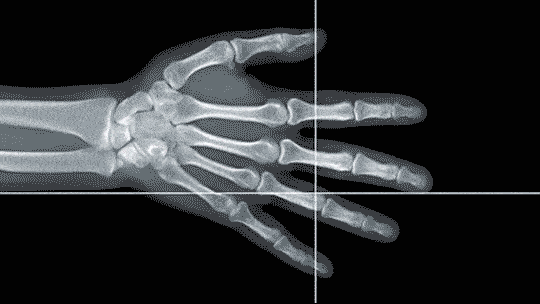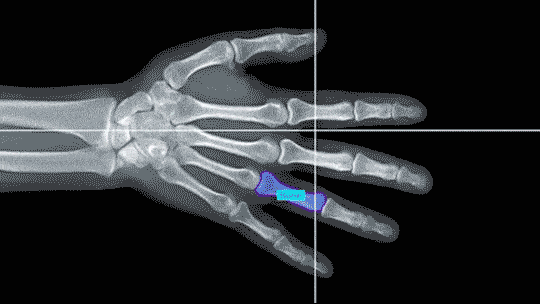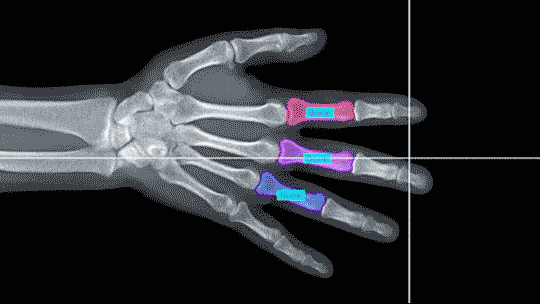
This method adds granularity to semantic segmentation by indicating how many times an object appears in a video frame.

Keymakr’s advanced video annotation tools and our professional in-house annotation team ensure the best results for your computer vision training data needs.
Annotating videos while tracking objects through multiple frames. Each object on the video will be recognized and tracked even through different cameras or separate video segments.

Keymakr’s advanced video annotation tools and our professional in-house annotation team ensure the best results for your computer vision training data needs.
Annotating videos while tracking objects through multiple frames. Each object on the video will be recognized and tracked even through different cameras or separate video segments.
Video annotation use cases
Video annotation is a practice that involves labeling video frames with various segmentation attributes. It's helpful for many machine learning and computer vision projects. For example, you can use them to create a training dataset for classification, object detection, and a custom model for recognition.
These applications range from training and testing AI models to creating rich media content for sharing and collaboration. Train AI models with video keypoint data and a video annotation tool. AI-powered services are helpful in many industries, from large medical corporations to small management startups. Here are some examples:

In-cabin driver monitoring
Keymakr annotated over 500 hours of in-car video footage, featuring a variety of drivers and in-car scenarios.
Annotators labeled and tracked body and facial feature movements in each video. This data allows AI models to interpret human behaviour and give warnings if (for example) a driver is falling asleep.
This model can monitor drivers on the road and train new drivers. In addition, the data can train a system to detect unsafe behaviors and provide driver recommendations.
Security AI
Skeletal annotation of video data allows AI to interpret movement. It is possible to create video data that showcases a variety of human behaviours.
Annotators use lines to identify limb positions in each frame of CCTV footage. This data is then used to train security AI models, allowing them to identify when an individual is moving erratically or behaving in a threatening manner.
Security AI uses artificial intelligence (AI) for monitoring and detecting threats. It is an emerging technology that can revolutionize how we approach security. The next step is training an AI model based on the skeletal annotations in video footage and tracking.
SEMANTIC SEGMENTATION ON VIDEO
Video data can contain additional information for AI training by deploying semantic segmentation.
This technique separates each pixel in each frame into classes of objects.
Object detection is the most common type of semantic segmentation, which aims to identify objects by assigning them labels. Then, you can train a model to read how they relate. For example, the system could recognize the difference between the sky, fields, trees, and buildings in the footage using semantic segmentation.
INSTANCE SEGMENTATION ON VIDEO
Instance segmentation promotes granularity in video data by identifying each individual case of a particular class of object in every frame.
For agricultural AI this might mean outlining and labeling each individual animal across an entire piece of footage.
Video annotation services, like Keymakr, also support pioneers in the field of disaster management. For example, automated drones can search large areas to find missing people, identify flooding and survey damaged buildings. These applications are trained with polygon annotation and video data.
VIDEO ANNOTATION WITH POINTS
Often AI models are required to identify key points in video footage. To achieve this annotators work through thousands of frames locating important positions in each image.
The first step is to select the keypoint frames that need annotating. You can do these by hand or automatically with an AI model. The points are automatically detected and extracted to keypoints by an autonomous algorithm. In addition, you can use pre-trained object detection models to recognize specific retail objects. For example, when annotating retail footage, the annotator might need to identify a product in every frame.
Video annotation for medical imagery
In medical annotation for machine learning, doctors would have to markup different parts of the body and markup corresponding diseases. This process aims to enable medical researchers and clinicians to share, access, compare and analyze medical images. Use the skeleton tool, semantic segmentation, polygon, and bounding box annotations in the video annotation software.
The process of medical image annotation is not necessarily done by a single person but rather by a team with an understanding of the anatomy being imaged and how it relates to other structures in the body. As a result, medical image annotation can be used for many purposes, such as identifying tumors, monitoring lesions, or finding abnormalities within organs.
Bitmask annotation for shapes
Bitmask annotations are an excellent way to label frames quickly without drawing on them. They use a binary mask to markup specific things. You can use it to markup particular objects or places you want to highlight or denoise footage frames by removing unwanted details.
This method uses segmentation to identify specific objects, like soccer balls or players. It uses keypoint dots to represent objects in a scene's location and size (radius). The points are connected by lines to show the shape of each object.
Video ANNOTATION WITH LINES
Line annotations are often applied to images of linear objects, such as: roads, pipelines, and electrical wires.
Keymakr produces line annotation for automated vehicle training. By locating markings and boundaries in video footage annotators help AI models to operate within the safe limits of the road system.
Lines help show the location of linear features on maps or aerial imagery. You can also use them for contour lines, architectural plans, building facades, and topological information.
SKELETAL VIDEO ANNOTATION
Charting and analysing the movements of the human body in video is an important application for machine learning models.
Skeletal annotation reveals how the body navigates from frame to frame.
Annotating with a skeleton is done by tracking skeleton points on a person's body skeleton, then connecting keypoints with lines. The result represents the body's skeleton appearance at that moment. It allows semantic segmentation to understand how people's skeletons move when exercising or playing sports.
Custom annotation for robotics
You can create a custom annotation for your most complex projects. For example, this tool can be helpful in robotics when you markup specific objects. If you're using a robot arm to move around and pick up objects, you might wish to stop the arm at points on the floor so that it won't interfere with other people or things in its path.
Contact Keymakr to discover how to create a custom tool that you can use for your robotics projects. We can help you create a key tool that works for your needs, whether for computer vision or other industries. Combine tools like the skeleton and semantic segmentation tools to meet your project goals.
Video annotation for inventory management
Inventory management is one example of where semantic segmentation technology could prove helpful because it could help businesses identify items in stock without having anyone physically check everything in the store.
Inventory management software often uses video annotation to create training data for machine learning applications. The resulting data could help management determine which products need restocking or replacement based on sales volume and trend analysis.
Polygon annotation for irregular objects
Use the polygon tool for more precise boundaries than the bounding box. The polygon is ideal when defining a specific area, such as a pasture. It's also great for drawing markup boundaries around irregular objects on each keypoint. For example, livestock management requires a particular area to be defined, such as a pasture.
The polygon tool works best for objects that are simple in shape and size. The more complex a thing is, the harder it will be to define with a polygon. When working with irregular objects, the polygon tool lets you draw a more accurate boundary around your object.
INDUSTRIES THAT WE SERVE:


Automotive
Automotive annotation is essential to machine learning and computer vision projects in the automotive industry. Human experts must identify relevant objects and add annotations using semantic segmentation to markup frames.


Security
CCTV footage annotation, traffic monitoring, person or object tracking through multiple cameras and video frames.


Medical
Just tell us what your project requires, and we will deliver. We offer medical video collection and annotation by certified medical professionals.


Robotics
From delivery robots to an “eye” in the production line, we can help you do it all. Our video annotation services are here to facilitate the countless applications of robotics AI.


Aerial
There are many uses for drone AI, however, these models require high quality datasets. We annotate drone footage for agricultural applications, object tracking, advanced monitoring systems, disaster monitoring and management and more.


Agriculture and Livestock Management
We have a wealth of experience with farm drone footage annotation, real time crop monitoring and ripeness detection, as well as video footage annotation from farm cameras for livestock management and counting.


Waste Management
Video annotation for sorting facilities will help to identify what can and can’t be recycled without risking human exposure to potentially toxic or hazardous waste.


Retail
The use cases for retail AI, trained through video annotation, are numerous. For example mapping customer’s paths through the store or tracking objects from security camera footage for loss prevention.


Sport
We annotate videos for sport analytics and fitness applications, tracking every change in body position and alignment.
Video Annotation Explained: What is AI video annotation, and how does it work?
Annotation is helpful in many areas of artificial intelligence, including computer vision and natural language processing. A typical use case might be marking up a keypoint or skeleton whenever an object appears in the frame. Then, machine learning systems can tell the difference between objects and understand their relationship with others in the footage using semantic segmentation.
Let's say you want to build an image recognition system of high quality to detect whether someone is happy or sad based on their facial expressions. You may need to markup hundreds or thousands of tagged videos showing various emotions in different lighting conditions and at different distances from the camera.
If an AI computer vision system knows what everything looks like, it can then understand what's happening in each frame and make predictions about future events based on its knowledge of what certain things look like.
What is video annotation?
Video annotation is like image labeling but with some crucial differences. You can't draw out boxes around objects like you can with images. There's a beginning and an end, so it's impossible to markup every pixel in a frame. In addition, videos are inherently time-based.
Keypoint annotation applies markup tags to data (usually done by humans). The result is a set of tags for each frame that describe what's happening. They're a way to train AI, deep learning, and computer vision models.
Manual human labeling is the most popular approach to labeling each frame. It can be tedious for large datasets, but the advantage is that it's fully customizable. There's no limit on how much detail you can put into each frame.
Automatic labeling involves machine learning to markup frames automatically without any human intervention. Automated methods tend to be faster and more accurate than manual markup approaches but require significantly larger datasets than manual methods (making them harder to reproduce).

Uses for annotated video
There are many uses for annotated data, but one of the most relevant ones is feeding markup training data to a machine learning model for markup. The prominent use cases are training and evaluating algorithms.
For example, when training an AI model to detect objects in images, you can give examples of what those objects look like with tags that identify them in the frames. Or, if you want to test whether your algorithm can recognize objects in different lighting conditions or from different angles, you can feed it videos with labels showing how the algorithms perform.
You can use annotated data for AI in several different ways:
- Object identification: Identity, track, and markup objects with computer vision.
- Action recognition: Recognize and tag actions like "walking," "skipping," and "jumping" in each keypoint.
- Motion capture: Tracking and labeling skeleton movements.
- Visual search: Tag keypoints of interest, products, or item properties.
- 3D camera tracking: Plot 3D information about a scene.
- Facial recognition: Identify and markup faces with tags using computer vision.
- Behavior prediction: Predict future movements based on prior behavior.
Through annotating, humans teach machines to detect and label objects, actions, and other features by providing examples. Machine learning models learn from annotated frames by recognizing patterns.
Types of video annotations
You can classify several annotations as either ground truth or user-generated. Ground truths are created by a human labeling expert who manually labels each video frame with one or more concepts.
For example, suppose you're trying to detect pedestrians in a street scene. In that case, your ground truth will include an image markup showing where each pedestrian is located and how they behave.
While ground truths can be of high quality and accurate, they tend to be expensive to create. On the other hand, user-generated ones are made by people labeling interpretations. As a result, most research in computer vision uses user-generated annotations instead of ground truths.
It's essential to have a well-defined labeling process. This process ensures that everyone looks at the same thing when they label footage and that labels are consistent.
How video annotation works
Video annotation is a process of identifying objects and events in content and then labeling those objects and events with the appropriate markup labels and video labeling tool. Machine learning algorithms can then use these labels to build models that can be used to extract meaningful information.
Scene recognition is the task of detecting the scenes. This type is helpful for training models that predict what kind of scene they see in each frame. For example, one could detect whether a scene contains people eating, playing sports, or entirely different.
Object detection is detecting objects using machine learning techniques like deep learning or convolutional neural networks (CNNs). These services are also known as computer vision because they rely on computer algorithms to see what human eyes see, like a skeleton and semantic segmentation. This annotation type helps train models that predict where objects are in the footage.
Facial recognition is often used to identify people based on their faces, which can be helpful for quality security applications such as biometric identification. Facial recognition detects faces in footage using keypoints and machine learning techniques like deep learning or CNNs. It helps train models that predict what part of a person's face is visible in frames.
The Video Annotation Process: How to annotate videos for AI training
There are many different types, but one of the most important is annotation, specifically human-generated ones that describe what's happening. They are a crucial component of training AI systems. They provide the labeling data needed to train machine learning algorithms and help improve the performance of those algorithms over time.
How to Annotate a Video: A Step-by-Step Guide
It's essential to test your model, and it's also important to iterate. You'll want to repeat this cycle repeatedly as you train your models. Test your model using a similar dataset but not identical to the one you trained it on. If possible, select a different set of examples that are more challenging than those presented during training.
Every data annotation tool will be different, but here is an example of how to annotate:
- Import or upload the files into your annotation platform and create a new project.
- Add your selected clip to the project (e.g., drag and drop).
- Make sure you save all changes before proceeding. Otherwise, you may lose your work.
- Annotate the keypoint frames with the chosen tools and markup labels (e.g., cuboids,
bounding boxes, skeletal, skeleton, lines, points, bitmap, semantic segmentation, etc.) - Export them for use in your machine-learning project. The tool will allow you
to export various formats, including JSON and XML.
Evaluate results by comparing your predictions against ground truth labels (i.e., correct answers). These will tell you how well your model predicted frames of footage. Tweak hyperparameters, such as learning rates or batch sizes, and re-train until performance improves sufficiently for validation purposes (e.g., above 95% accurate). Repeat until achieving desired results.
Selecting labels for your video annotation project
Labeling training data is a key step in building machine learning models. Without suitable labels, it isn't easy to make accurate machine-learning models. The wrong labels can lead to false positives and negatives, which can ultimately affect the accuracy of your model.
Here are some tips for choosing the correct labels for your project:
- Label each object with an identifier to track them in footage frames over time.
- Add additional information about each object using semantic segmentation.
- Use markup labels with different levels of specificity based on what type
of keypoint analysis you want to do with them.
If you're trying to train an object recognizer, ensure your model can distinguish between what it's supposed to detect and what it's not. For example, suppose you're training a model that sees people playing basketball in a clip. In that case, it should be able to tell a person from a ball or another object in the vicinity.
Video annotation services and tools
Video annotation is a labour intensive process that requires a significant investment of time and resources. Consequently, many AI companies looking for data annotation make use of automated annotation tools to accelerate this process. Alternatively companies can collaborate with annotation service providers, like Keymakr, and access high-quality, scalable video annotation.
Do you need automatic video annotation?
You can markup objects in frames with either manual or automated methods. Manual labeling usually involves marking up an image with bounding boxes around each thing you want to annotate. It's a tedious and time-consuming process. However, automated labeling uses computer vision techniques to automatically identify and segment individual objects in the footage.
When training AI, the more data you have, the better. Automated annotation is a good choice because it helps you quickly build up a large dataset. The same goes for annotating. If your clips are annotated and tagged, adding them to your training set will be easy. Automated annotation can be faster and improve your time management.
But what if you want a new label for all your footage? That's when the manual annotation is better suited. Manual tagging allows users to use specific markup categories. Manual taggers can also correct errors in automatic tags and ensure accuracy across different sets of frames through careful monitoring.
Video annotation services
Video annotation is a time-consuming and expensive process. It requires specialized skills, knowledge, and tools to produce high-quality results on time. Using Keymakr's management services and platform will help to reduce the time it takes to label your training data, allowing you to get your AI model out faster.
Keymakr's team has extensive experience labeling data for leading companies across multiple industries, including retail, medical, management, financial services, and healthcare. In addition, our annotators and technology platforms continue to adapt to the fast-changing landscape of computer vision AI.
Keymakr's cutting-edge AI technology platform scales up quickly in response to increasing demand for our services. With Keymakr's AI-powered annotation services, you can get the best of both worlds. You'll have access to a highly skilled and experienced team of human annotators who can provide high-quality outcomes at an affordable price.
Automated annotation tools
AI can help with automatic semantic segmentation algorithms to identify objects in footage based on their shape and color characteristics. Then, annotate video frames using existing annotations or create new ones automatically by detecting keypoints in footage and creating bounding boxes, skeletons, and other shapes around them in real-time.
Some automated labeling tools use machine learning to identify objects in the footage. For example, you can train software to recognize objects in a particular category, such as wildlife or vehicles. Once trained, computer vision uses pattern recognition to locate similar images in other footage frames.
The KeyLabs platform is a leading automated service provider that automatically enables you to markup objects using artificial intelligence (AI) and machine learning. These technologies are used in many industries, including law enforcement, healthcare, education, management, robotics, and research.
In addition to speeding up the process, autonomous tools can save management money by reducing manual labor costs associated with manual markup labeling. The platform uses deep learning technology to analyze frame-by-frame to detect objects and their attributes, such as position and skeleton movement patterns.
Our automated platform can identify objects within various scene types, including outdoors, indoors, and crowded scenes, and object categories, including people, vehicles, skeletons, and animals. As a result, it can accurately identify the same object across multiple frames.
Video annotation services vs automated video annotation
Automated video annotation tools can create large video datasets quickly and affordably. Automation can also reduce labour costs and management pressures. Despite these strengths automated annotation can leave AI companies with a lack of support and lower quality video data.
Annotation service providers like Keymakr have a wealth of annotation experience, and Keymakr also gives AI companies access to proprietary annotation software. Annotation technology keeps data annotation tasks on schedule. In addition, outsourcing video annotation allows costs can be scaled up and down as data needs change.
Automated annotations can be cost effective but also tend to contain significant errors that impede development. Keymakr’s annotation teams work together, on-site, and are led by experienced team leaders and managers. This allows for far greater communication and troubleshooting capabilities, and ensures that video annotation quality remains at a high level.

- Smart task distribution system. As part of the service provided by Keymakr, companies in need of video annotation have access to the unique features of Keymakr’s annotation platform. This also includes an innovative smart task distribution system that assigns tasks to annotators based on performance metrics and suitability. This helps to keep annotations precise across video datasets.
- 24\7 monitoring and alerts. The Keymakr platform allows managers to see real time information about the status of their project. The platform can send alerts to managers when there are recurring issues with data quality or if a particular task is behind schedule.
- Vector or bitmask. Keymakr offers both bitmasks and vector graphics for video annotation projects. Keymakr can convert both image types if necessary.
Best practices, challenges, and future opportunities
Video annotation has been around for decades, but its use has grown considerably in recent years. It is now widely used in machine learning (ML), deep learning, and artificial intelligence (AI). In these fields, it's used to train ML algorithms and improve the performance of existing computer vision systems. Below are the best practices, challenges, and future possibilities.
Video annotation best practices
There are several best practices for manual annotation. Below are some tips to keep in mind when you're manually annotating footage frames.
- Ensure the guidelines are clear, concise, and easy to follow. Annotators should
understand what management expects them to do in one or two minutes at most.
Another best practice is for software vendors to provide training materials that
explain how annotators should perform manual tasks. (e.g., when to use the skeleton
annotation). For example, you can make a video showing an example of labeling frames. - Second, keep an eye on quality control by checking each markup manually and
ensuring it's consistent across different frames. This step is crucial when creating
large-scale projects with multiple annotators simultaneously working on different data sets. - Third, have a method for tracking changes made by different users. For example, you
could use a spreadsheet that lists each labeling markup made by annotators, including
the content of those changes. This list makes it easy for management to spot
inconsistencies or mistakes in the data set. - Consider using a classification model to create new labels. Classification models use
machine learning to identify patterns in frames and are often used for image recognition. - Last but not least, when working with an extensive data set, it's essential to
consider the limitations of your human annotators and platform. You won't be able
to get everything done in one go; instead, focus on getting a good start
and then iterating over time.
Consider using machine learning if your data set is too large for manual labeling.
Challenges in video annotation
Annotation is an incredibly challenging task. Unlike static images, videos contain many high-dimensional data, making it difficult for computer vision to recognize objects and events. In addition, the medium is dynamic and complex and often requires the human eye to understand fully. Data management is another factor considering the size of files.
For example, if you want to detect people in footage autonomously, you'll need to teach computer vision how they move. Therefore, you'll need many examples of people walking in different situations so that the computer vision can learn what constitutes a person (e.g., their size, skeleton, and speed), how they move relative to one another, and their environment (e.g., whether they're running or walking).
In addition to the time it takes to annotate data manually, many other factors can affect accuracy and consistency. For example, suppose a tool offers multiple ways of tagging the same content (e.g., by providing different fields for each label). In that case, users can choose different markup labels for similar content management.
To overcome these challenges, researchers developed several new approaches that can automatically extract and markup content. One of the most popular methods is based on machine learning (ML), which provides computers with the ability to read data without human intervention.
Machine learning algorithms learn how to solve problems without being explicitly programmed by humans. For example, instead of requiring users to tag thousands of videos manually, machine learning can autonomously extract data and markup content with accuracy and consistency far beyond what humans can achieve.
The future of video annotation
The future of annotation is bright. The need for human labelers will decrease as computer vision algorithms become more powerful and ubiquitous. New technologies such as deep learning will enable computer vision researchers to build more powerful tools for annotating.
Researchers will build better models that can generalize to new data and perform well on unseen data. For example, deep learning models trained using humans perform significantly better than those without. These results apply in many applications, such as video classification and localization.
Expect new services, including ones automatically generated by computer vision based on an algorithm's ability to analyze the content. The future will likely include management tools that automatically enable us to create projects at scale using machine learning algorithms.
We'll likely see a key shift from standalone tools to ones integrated into other platforms. These new tools could help us better understand what's happening, which would be valuable for medical imaging, security, and surveillance applications.
For example, researchers could develop algorithms that automatically annotate based on what they find in medical imaging or security footage. In this scenario, computer vision would analyze the content and then generate annotations for us to review and approve.
Conclusion and reference links to relevant materials
Video annotation is a vital tool in the fields of machine learning, deep learning, and artificial intelligence. There are several best practices to keep in mind when manually annotating footage, such as providing clear guidelines and tracking changes made by different users.
However, annotation is challenging, with factors such as data management and the dynamic nature of videos affecting accuracy and consistency. Researchers have developed new approaches based on machine learning to overcome these challenges.
Machine learning can automatically extract and markup content with higher accuracy and consistency. The future of video annotation looks bright, with the potential for increasing automation and developing new technologies such as deep learning.
Check out the reference links and materials below to read more about video annotation.
- Combating Climate Change With Computer Vision Video Annotation
- 9 Ways Smart Cities Use Video Annotation for Computer Vision
- Improving Retail AI Systems With Video Annotation
- Butler Robots and Video Annotation
- How Video Annotation Supports Autonomous Vehicles
- Video Annotation is Essential for Security AI
- Aerial Technology Depends on Video Annotation



















