
Multimodal LLM: Visual-language models that understand images and text
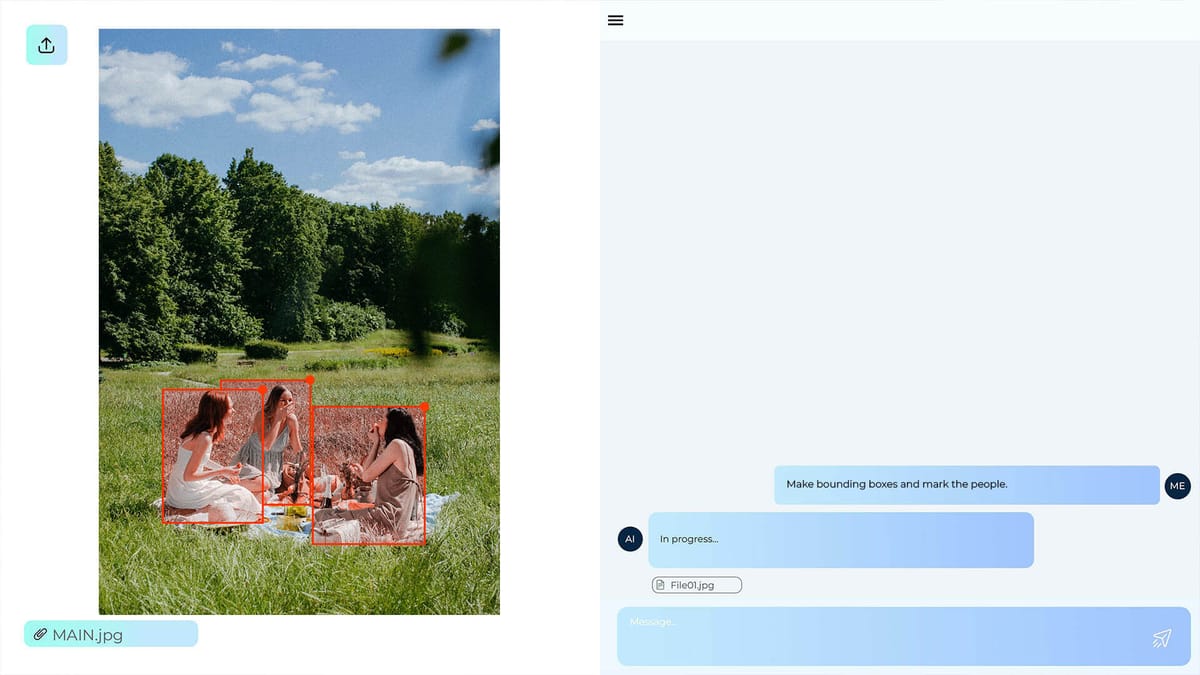
Systems that combine image and text data can reduce interpretation errors in real-world tests. By combining image grids, text sequences, and audio signals, these language models gain richer context for better understanding and generation. These multimodal AI systems leverage multiple modalities for improved context.
Each type of input uses a dedicated encoder - text encoders like BERT, image encoders like ViT or CNN. Projection layers then align the features into a common embedding space, enabling the model to consider different formats. Image encoders are critical for image understanding, allowing the system to extract meaningful visual features.
Fusion ranges from simple pooling to attention-based cross-attention, which associates words with image regions. Decoders support signature generation and classification headers for VQA and detection.
Key Takeaways
- Fusing image and text data improves context and reduces errors in subsequent tasks.
- Individual encoders create robust features that projection layers combine to think together.
- Attention-based fusion associates words with visual areas for accurate results.
- Decoding supports captioning, VQA, and detection workflows in production.
- VLM training and instruction tuning enhance the model’s capability for visual reasoning and accurate multimodal outputs.
- Practical deployment favors better data and focused models over uncontrolled scale. These strategies are essential for robust multimodal AI applications in real-world tasks.

What is a multimodal LLM?
A multimodal LLM is a large language model that simultaneously processes and combines multiple data types (modalities), such as images, audio, video, and structured data.
Multimodal systems integrate multiple sources of information into a single representation, enabling them to understand context better and perform more complex tasks. Such models can analyze images and generate text descriptions, answer questions about image content, interpret graphics, combine text with visual data, or even process audio signals alongside text.
Architecturally, multimodal LLMs combine a language model with additional encoders for other data types, and then combine their representations in a common feature space. This allows the system to perform cross-modal tasks, such as visual question-and-answer, automatic image captioning, multimodal search, or video analysis with text explanations.
Multimodal LLMs are used in fields such as computer vision, media analysis, robotics, autonomous transportation, medicine, and intelligent assistants.
Basic building blocks
Encoders are the foundation that transforms raw pixels, waveforms, and tokens into useful functions.
Text tokenization and embedding
Text cannot be processed directly by neural networks, so it first undergoes a tokenization step - breaking the text into smaller units called tokens. These are words, parts of words, or individual characters. After tokenization, each token is converted into a numerical vector using an embedding mechanism. The result is a sequence of vectors that reflect the semantic and syntactic relationships between words. This representation is fed to a language model that analyzes the context, determines token dependencies, and generates additional text or responses.
Vision encoders: ViT and CNN
Multimodal models use specialized computer vision architectures to process images. The Vision Transformer splits the image into small patches and processes them like a transformer model processes text tokens. This allows the model to detect global dependencies between different parts of the image.
Another approach is the Convolutional Neural Network, which uses convolutional filters to detect local visual features such as edges, textures, and shapes.
CNNs are used for classification, segmentation, and object detection, while ViTs are used in modern multimodal systems due to their better integration with transformer architectures.
Audio encoders and pipelines
Audio data has a temporal structure, so before being fed to the model, it undergoes several processing stages. First, the audio signal is converted to a spectral representation. Then, the audio encoder converts this data into vector embeddings that can be integrated with other modalities. In multimodal systems, the audio pipeline comprises signal preprocessing, acoustic feature extraction, encoding, and synchronization with text or video. This allows the model to perform tasks such as speech recognition, sound event analysis, or combining audio with visual context.
Projection and shared embedding spaces
In multimodal LLMs, different types of data are first processed by separate encoders that transform them into vector representations. However, these representations are initially in different feature spaces, so a projection and a shared embedding space are used to combine them. Its goal is to transform vectors from different modalities into a common format that allows the model to compare and combine information regardless of their source.
To reconcile different representations, adapters and projectors are used for aligned features. A projector is a small neural network or linear layer that transforms the output of an encoder for a particular modality into a vector of the appropriate size, aligned with the language model's space.
Adapters perform a similar function, but are inserted into the existing model architecture as additional layers that adjust the data representation without completely rebuilding the entire network. Thanks to such components, the model learns to align the semantic features of different modalities.
An important approach in building multimodal systems is the use of frozen backbones and special training strategies. In this case, pre-trained encoders remain unchanged during the training of a multimodal model, while only additional components, such as projectors, adapters, or alignment modules, are optimized.
This strategy allows for reducing computational costs while preserving the knowledge already learned by large models. In addition, it helps stabilize the training of multimodal systems and simplifies the integration of different types of models into a single architecture.
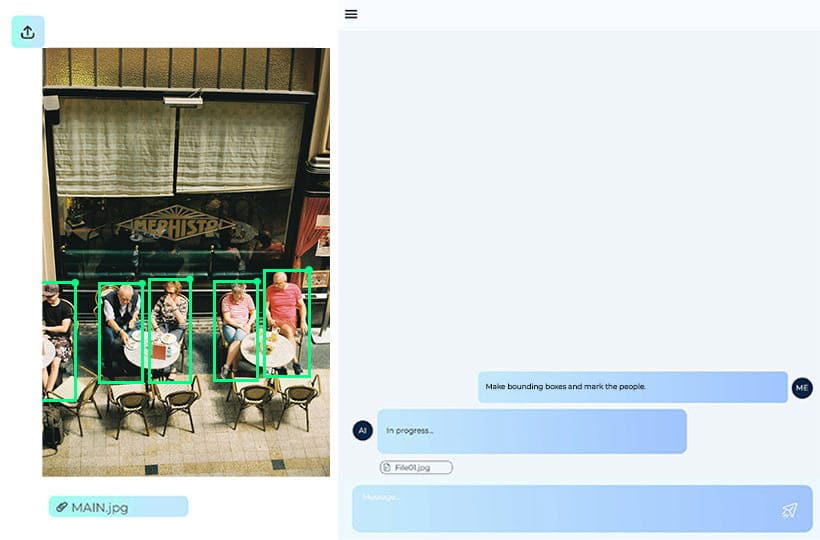
Two dominant architectures for multimodal LLMs
The model's architecture determines how modalities are combined and how semantic relationships are established between them. In practice, two approaches have become widespread: a unified embedding-decoder approach, where all modalities are transformed into common tokens and processed by a single language model, and cross-modal attention, where different modalities interact through special attention mechanisms within the transformer layers. Both architectures have their advantages and are used depending on the task, the amount of data, and the complexity of the multimodal interaction.
Challenges and risks limiting deployment
Real-world systems have limitations in context handling, instruction precision, and cross-modal logic. These gaps slow down implementation and increase operational risk.
Models worth knowing
In 2025–2026, the development of multimodal LLMs has been actively accelerated by new models that integrate text, images, and other modalities in novel ways. They demonstrate differences from previous systems in how they process and combine data, allowing greater consistency across modalities and enabling more complex tasks.
Llama 3.2 vision language
This is a multimodal version of the well-known text model LLaMA, which is trained on both text and visual data. The main difference is the integration of images into the transformer decoder, enabling the model to provide accurate image descriptions and to combine visual content with text instructions.
BLIP-2
BLIP-2 uses an approach that combines a pre-trained visual encoder with a language transformer via special "Q-Former" adapters. This allows integration of information into the text space, reduces the need for complete retraining of the model, and speeds up training on new data.
Flamingo
Flamingo has a cross-modal attention architecture within its transformer layers to combine text and images during attention computation. This improves the accuracy of image question answers and enables the model to handle data sequences of different types flexibly.
LLaVA
LLaVA focuses on user interaction and combines text and images using unified tokens. It can perform complex multimodal tasks, such as explaining image details, answering questions, and analyzing content in a question-and-answer format.
MiniGPT-4
MiniGPT-4 combines a pre-trained large language model with a visual encoder via small adapters, enabling rapid integration and supporting multimodal dialogues. The main innovation is easy scalability and the ability to train on limited multimodal datasets without loss of quality.
FAQ
What is a visual language model, and how does it differ from a standard language model?
A visual language model combines text and image processing in a single representation, while a standard language model works only with text data.
What modalities do these systems typically support?
Modern multimodal LLMs support text, images, and audio or video as primary modalities for integrated analysis and content generation.
What are the main building blocks of a multimodal model?
The main building blocks include encoders for each modality, text tokenization and embedding, adapters and projectors for aligned features, integration mechanisms in a common embedding space, and transform decoders or cross-modal attention layers for data fusion.
What fusion strategies are used to fuse modalities?
Multimodal LLMs use token or vector pooling strategies, cross-modal attention, and joint projections into a single embedding space.
What recent models illustrate different design options?
Examples include variants of the Llama 3.2 vision-language model that use cross-attention with a frozen LLM and a trained ViT. BLIP-2 and Flamingo combine vision and language through cross-attention. LLaVA or MiniGPT-4 focus on instruction execution using synthetic instruction datasets.
What are the main risks and challenges of deployment?
Challenges include gaps in cross-modal reasoning, bias and robustness issues, high computational overhead, and the management of lifelong learning.
