
LLM training data quality
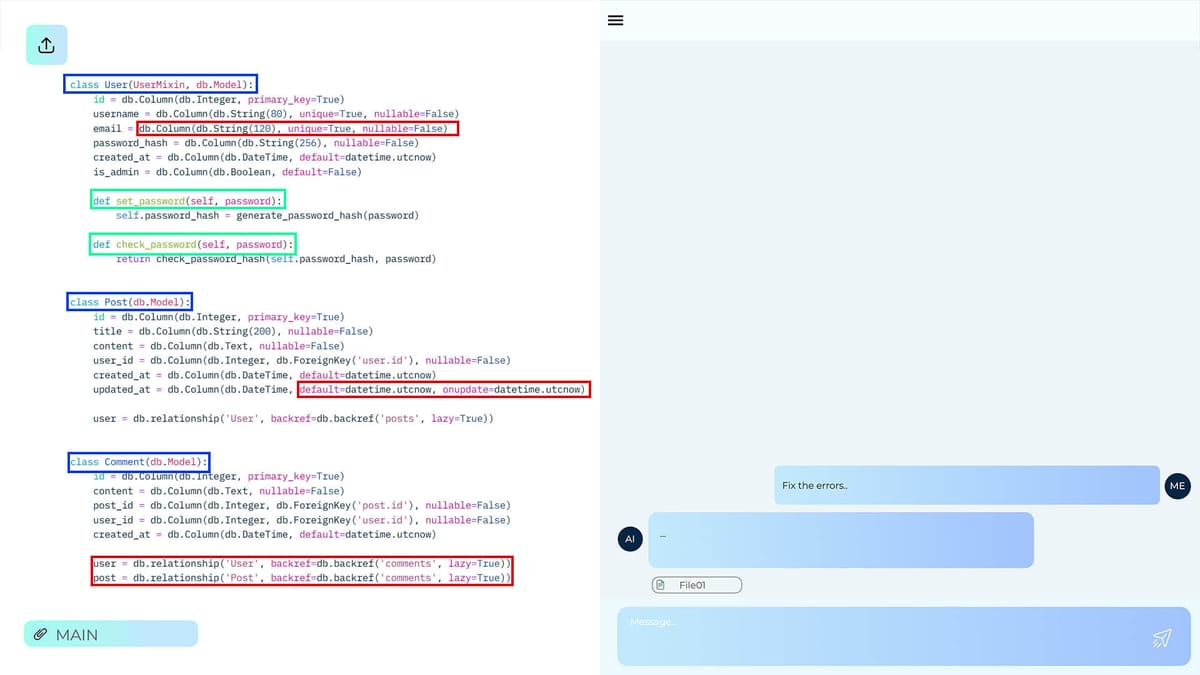
Data quality is essential for training large language models (LLMs). High-quality data annotation, careful dataset curation, and effective data filtering ensure the accuracy and reliability of models. Adherence to annotation standards and implementation of quality assurance systems can minimize errors, reduce bias, and improve performance in real-world applications.
Quick take
- Input selection at the scale of trillions of tokens is a major factor affecting model performance.
- Decoder-only models rely on tokenized information to learn the next word.
- Pre-training and fine-tuning have different curation needs and risks.
- Higher input standards reduce computational waste and improve generalization.
- Governance and contracts support standards over time.

Why data quality is crucial for large language models
Data determines what and how a model learns to understand, generalize, and generate. Large language models are based on the principles of machine learning and deep learning, in which they learn patterns from large amounts of text rather than being explicitly programmed. If the training data contains errors, biases, or irrelevant information, the model reproduces these shortcomings in its responses. This leads to so-called hallucinations, inaccuracies, and even systematic distortions, which can be critical in real-world domains.
High data quality ensures better generalizability of models. When the data is structured and diverse, the model can correctly handle new queries.
Low-quality or homogeneous data limits its ability to adapt to different contexts and language variations. Data balance is important; if certain topics or perspectives are disproportionately represented, the model exhibits bias, undermining its reliability and ethics.
Also important is the accuracy of the markup and the relevance of the data to the task. In learning processes such as Reinforcement Learning from Human Feedback, the quality of instructions and evaluations affects the model's behavior. Inconsistent or incorrect annotations lead the model to learn unwanted patterns or misinterpret user queries. Therefore, data quality is the foundation on which the security and trust of large language models are built. Even the most sophisticated architecture cannot compensate for poor data, whereas a high-quality, cleaned dataset increases the model's accuracy and stability.
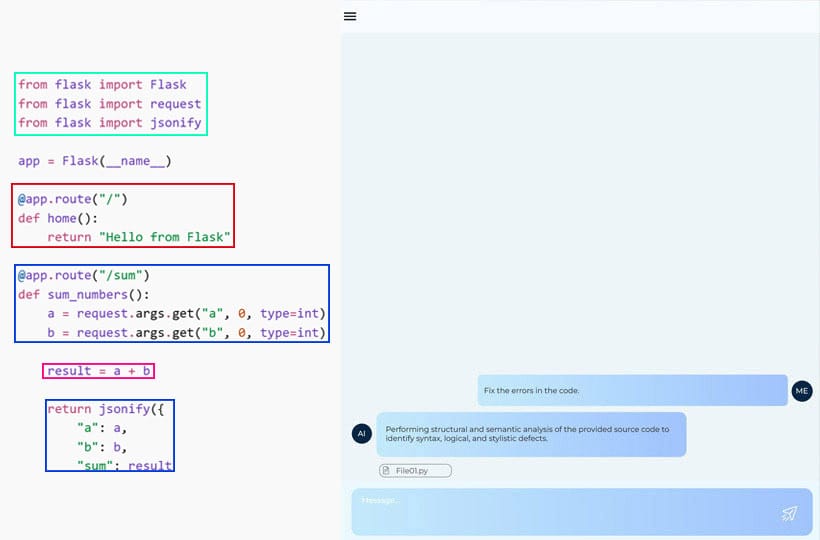
Key dimensions of training data quality and their correlation with performance
The quality of training data is the foundation of the effectiveness of large language models at all stages. Various dimensions of data quality shape a model's ability to generate relevant and consistent responses. Understanding these dimensions and their impact on performance enables us to evaluate datasets and improve model performance in practical scenarios.
Challenges undermining data quality at large scale and how to address them
As data volumes grow, it becomes more difficult to control their consistency and prevent the accumulation of errors and biases. Scaling leads to automation of collection and labeling, which increases the risk of noise, duplication, and uncontrolled distortions. Understanding the challenges and approaches to addressing them allows you to build robust data preparation pipelines for large language models.
Model quality assessment: Human gold standards and automated proxy measurements
Evaluation of the quality of large language models is based on two approaches: using human "gold standards" and automated proxy metrics. Human gold standards involve evaluating the model's output by experts or well-trained annotators who establish a reference quality standard for the responses. This approach allows for accurate measurement of the relevance, consistency, and contextual correctness of responses, but it is resource-intensive and difficult to scale to large datasets.
Automated proxy measurements use algorithmic metrics to assess model performance on large datasets quickly. These include comparisons with reference responses, assessment of consistency between repeated queries, style and grammar checks, and application of specialized tests for specific domains. These methods allow you to identify errors and trends in model behavior quickly. Still, they do not always take into account the complex context or subtle nuances that are noticeable to an expert.
Modern evaluation practices
Benchmarking-style evaluation involves using standard test suites to compare models across various performance metrics.
Scaling open evaluation enables you to involve a wider range of reviewers or users to collectively provide quality ratings, thereby increasing representativeness and reducing the bias of individual raters.
The design of a mixed-process approach combines the strengths of both approaches: human ratings are used for important or complex cases. At the same time, automated metrics quickly verify a large number of results.
Data-focused curation: Manual, heuristic, and model-based filtering
Data curation is a stage of training on large datasets, as errors or noise in the data affect the performance of language models. Modern curation approaches focus on improving data quality before training or retraining models. They filter out incorrect or biased examples, thereby increasing the model's accuracy and consistency.
The main strategies for data curation
- Manual filtering involves experts or annotators checking, correcting, and selecting examples. This method provides high accuracy and reliability but is resource-intensive and difficult to scale for large datasets.
- Heuristic filtering is the application of rules, patterns, or simple algorithmic checks to detect noise, duplicates, or incorrect data. This method allows you to process large amounts of data quickly, but may miss complex cases or make mistakes in ambiguous examples.
- Model-based filtering uses pre-trained models to assess data quality, detect errors or anomalies, and predict the relevance and consistency of new examples. This approach combines scalability with high automation and flexibility, especially for large, dynamic datasets.
Model-driven curation: tuning outputs to fix the training set
Model-driven curation is a modern approach that uses the models themselves to detect and fix problems in a dataset. The idea is that a pre-trained model analyzes the data, generates quality scores, and identifies anomalies, inaccuracies, or examples that do not meet the target task. Based on these signals, the training set is adjusted, noise is removed, errors are corrected, or problematic examples are further annotated.
This approach allows you to automate the cleaning of large datasets and integrate model feedback into the dataset preparation process. For example, the model can suggest which examples are contradictory or which answers are inconsistent, so that annotators or automatic processing systems can focus on critical cases. Also, model-driven curation helps detect structural or semantic problems that are difficult to detect with simple rules or manual inspection.
This approach is effective at large scales, where manual verification becomes time-consuming and simple heuristics cannot account for complex contextual dependencies.
Data governance and contracts
This approach allows for the definition of clear rules and standards for data collection, annotation, and processing, and reduces the risk of noise, errors, and bias.
Data contracts establish formal obligations for vendors, annotators, and internal teams, which increases transparency, accountability, and auditability at each stage of data processing.
Data governance and quality assurance process
Defining standards, verifying all stages, and aligning stakeholders. This stage establishes clear data quality criteria, establishes requirements for data structure, accuracy, and representativeness, and ensures consensus among all stakeholders. This provides the foundation for a robust and controlled data preparation process.
Bias reduction, accountability, and audit are built into pipelines. This stage integrates mechanisms for monitoring and correcting bias, documents decisions and data changes, and implements quality audits at each stage of processing. Built-in checks automatically detect anomalies and deviations from standards, ensuring stable, ethical training of training sets for large language models.
Applying such practices improves data quality and makes the entire training process scalable and controllable, which is critical for the reliable operation of large language models in real-world applications.
Privacy-enhancing strategies
Privacy is important when working with large language models, especially in areas such as medicine, finance, or personal services. The main goal is to ensure that data can be used safely to train models without risking the disclosure of private information.
A key approach is data anonymization, which involves removing identifying features such as names, addresses, phone numbers, and other personal data. This allows you to preserve valuable information for training models while reducing the risk of privacy breaches. Anonymization is done at different levels, from simple masking of individual fields to complex algorithmic transformations that transform the data.
A less useful approach is to use synthetic data generated by models or algorithms that reproduce the structural and semantic characteristics of the original data without directly copying specific records. Synthetic data enables you to create large, diverse training sets while reducing the risk of leaking confidential information. It is effective in combination with anonymization, when partially real data is transformed or supplemented with synthetic examples to increase the volume and quality of the training set. The combination of anonymization and synthetic data in practice strikes a balance between privacy protection and the model's need for high-quality, diverse data.
FAQ
How does poor training data affect model performance?
Poor training data leads to reduced accuracy, generalizability, and model robustness.
What are the main differences in the requirements for pre-training and fine-tuning datasets?
Pre-training datasets require large, diverse data to build broad language knowledge, while fine-tuning requires smaller, specialized, and well-labeled data that is task- or domain-specific.
What are some best practices for identifying and removing problematic examples?
Best practices include manual annotation, heuristics, deduplication, automatic anomaly detection, and model-driven filters to identify and remove problematic examples.
When should examples be filtered rather than corrected?
Examples should be filtered when their errors or inconsistencies are so significant that correction would require disproportionate resources or would not ensure the reliability of the data.
What human and automated assessments best measure model reliability?
Model reliability is measured by a combination of human expert assessments for contextual accuracy and consistency and automated metrics such as precision, response consistency, and anomaly detection in outputs.
When is synthetic data useful, and what risks does it introduce?
Synthetic data is useful for increasing the volume and diversity of training sets, but it can introduce errors or inaccuracies that distort model behavior.
