
LLM Fine-Tuning: Complete Guide to Domain-Specific Model Adaptation [2026]
![LLM Fine-Tuning: Complete Guide to Domain-Specific Model Adaptation [2026]](/blog/content/images/size/w1200/2025/12/KMmain--49-.jpg)
The topic of fine-tuning large language models arises when it becomes apparent that general-purpose LLMs do not always behave as expected in specific tasks. A general model may be effective at supporting dialogue or answering broad questions, but when dealing with narrow topics, specialized terminology, or fixed-response formats, its behavior often proves to be unstable.
As models grow in size, parameter-efficient tuning approaches are increasingly used. They emerged not as a theoretical idea, but as a response to resource constraints and the difficulty of full retraining. For example, LoRA enables modifying the behavior of a model pointwise without affecting most of its parameters, making adaptation more manageable and easier to maintain.
Key Takeaways
- Adapting a pre-trained model improves domain fit and measurable model performance.
- Weigh full updates versus parameter‑efficient approaches for cost and speed.
- Evaluation needs both human checks and automated benchmarks before rollout.
- Distillation and offline inference cut serving costs at scale.
- Responsible AI practices must be embedded in data and governance plans.

Understanding the LLM Lifecycle Fine-Tune
Fine-tuning large language models (LLMs) allows us to make them more accurate and useful for specific tasks. The base model is capable of answering a wide range of queries, but often fails to consider the domain-specific nuances, terminology peculiarities, or the user's preferred response style. Fine-tuning helps correct these limitations and adjust the model's behavior to meet specific requirements.
Modern approaches, such as parameter-efficient tuning and LoRA, enable the adaptation of the model without requiring a complete retraining of all parameters. This reduces computational costs and makes the process more manageable, while preserving the model's basic capabilities.
Fine-tuning an LLM can be used to train it to follow rules, work with highly specialized information, and provide more stable answers. This transforms a general-purpose model into a tool that is truly tailored to specific tasks and areas of use.
What Is LLM Fine-Tuning
LLM fine-tuning is a process that allows for making a large language model more “yours” for a specific task or domain. The base model is already capable of working with general-purpose text, but when accuracy is required in a specialized topic, response style, or specific rules, fine-tuning helps to adjust it.
Instead of completely retraining the entire model, parameter-efficient tuning methods are often employed, such as LoRA, which enables the model to adapt quickly with fewer resources. The result is a model that better understands the specifics of the data, gives more stable responses, and works effectively in a specific domain.
When to Use Prompt Engineering, RAG, or Fine-Tuning
Core Types of Fine-Tuning for Large Language Models
- Supervised Fine-Tuning (SFT) is a classic approach where a model is trained on input-output pairs from specific domain data. It is used to improve the accuracy of responses in specialized tasks.
- Instruction Tuning - the model is trained to better follow user instructions or queries, improving its ability to generalize and interact in different scenarios.
- Reinforcement Learning from Human Feedback (RLHF) - the model is adapted based on human ratings to improve the quality of responses, their correctness, and the desired style.
- Parameter-Efficient Fine-Tuning - methods that allow changing only a part of the model parameters instead of completely retraining. Examples include LoRA, adapters, and prefix tuning.
- Domain-Adaptive Pretraining (DAPT) - additional training of the model on a large set of texts of a specific domain before fine-tuning to strengthen its understanding of a specific topic.
- Hybrid Approaches - a combination of various fine-tuning methods and external mechanisms, such as RAG or tool usage, to achieve better accuracy and flexibility.
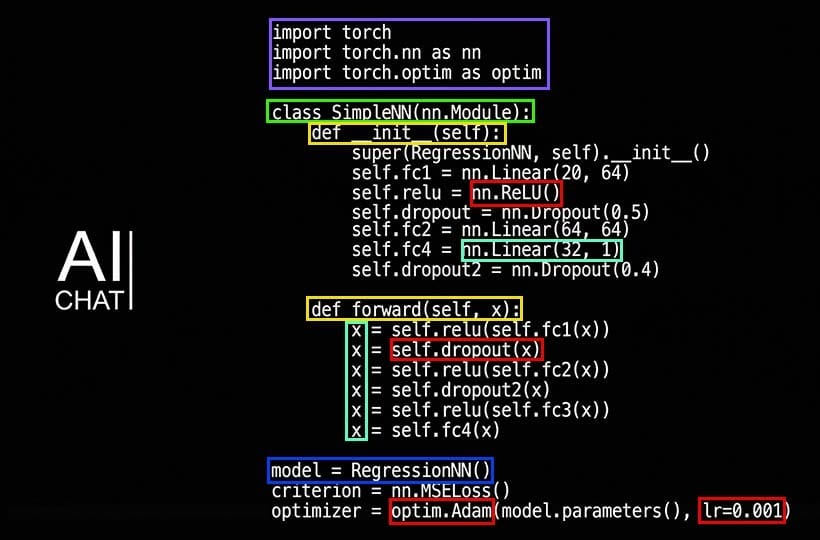
Parameter-Efficient Fine-Tuning Deep Dive
Parameter-efficient fine-tuning (PEFT) is an approach to adapting large language models that allows for changing only a small subset of the parameters, rather than retraining the entire model from scratch. The idea is to retain most of the knowledge of the underlying LLM while simultaneously adapting it to specific needs, response styles, or domain terminology. This approach is especially valuable in large models, where full fine-tuning can require terabytes of memory and powerful computing resources.
The most common PEFT methods include LoRA, adapters, and prefix tuning. In the case of LoRA, small additional matrices are added to the existing model weights, which are learned during adaptation, leaving the basic parameters unchanged. Adapters insert small blocks between the layers of the network that are responsible only for domain correction. Prefix tuning alters the representation of input tokens by adjusting the model through special “pseudo-tokens”. All of these methods enable the model to adapt quickly to small datasets without requiring a significant investment of time and resources.
One of the main advantages of PEFT is the ability to experiment with different domains simultaneously. Create several small adaptations for different tasks and connect them as needed without affecting the main model. This makes the process of integrating LLM into business processes or products much easier. Additionally, the parameter-efficient approach mitigates the risk of “forgetting” previously learned knowledge from the base model, which can sometimes occur during full fine-tuning.
At the same time, PEFT requires careful tuning: it is essential to select the appropriate hyperparameters, the volume of adaptation matrices or layers, and also to verify the stability of the model's behavior after making changes. An unsuccessfully tuned PEFT can lead to unstable responses or loss of generalization ability. Therefore, although parameter-efficient fine-tuning methods significantly save resources, they require planning, testing, and quality control.
The Seven-Stage Fine-Tuning Pipeline: From Data to Deployment
Risks, Governance, and Responsible AI
- Bias and fairness – Models can reproduce or amplify biases present in the data. Regular assessment for bias and fairness of responses is necessary.
- Hallucinations and inaccurate outputs – LLMs can generate false or misleading information. It is essential to validate the results and establish mechanisms for verifying their reliability.
- Data privacy and security – The use of sensitive or personal data needs to be protected and comply with GDPR, HIPAA, or other regulatory requirements.
- Model misuse – LLMs can be used for malicious purposes, including spam, fake news, and cyberattacks. Limitations and usage policies should be in place.
- Transparency and explainability – It is crucial to ensure that models are transparent and can clearly explain their decisions, particularly in critical domains.
- Governance and accountability – Implementing AI governance structures, identifying responsible individuals, and establishing risk assessment procedures helps control the use of models and adhere to ethical standards.
- Continuous monitoring and updating – Models require regular monitoring and updating to avoid quality degradation, account for changes in data, and maintain regulatory compliance.
FAQ
What is LLM fine-tuning?
Fine-tuning a large language model (LLM) involves adapting a pre-trained model to specific tasks, domains, or styles. It improves accuracy and consistency for specialized use cases.
Why is domain-specific fine-tuning important?
Domain-specific fine-tuning ensures that the LLM understands specialized terminology and context. This makes responses more precise and relevant for narrow tasks.
What are the core types of fine-tuning for LLMs?
The main types include supervised fine-tuning, instruction tuning, RLHF (Reinforcement Learning from Human Feedback), and parameter-efficient methods like LoRA and adapters. Each serves different adaptation needs.
What is parameter-efficient tuning?
Parameter-efficient tuning modifies only a small portion of the model's parameters rather than retraining the entire LLM. This reduces computational cost while maintaining the base model's integrity.
How does LoRA work?
LoRA (Low-Rank Adaptation) adds small trainable matrices to existing weights, allowing the LLM to adapt to a domain without updating all parameters. It is a fast and resource-efficient method for fine-tuning.
When should prompt engineering be used instead of fine-tuning?
Prompt engineering is ideal when quick results are needed without training the model. It works best for general tasks or when access to domain-specific data is limited.
What is RAG, and when is it useful?
RAG (Retrieval-Augmented Generation) combines LLMs with an external knowledge base. It is particularly useful when the model needs to work with large or dynamic datasets, as it provides accurate and up-to-date answers.
What are the main stages of a fine-tuning pipeline?
The seven stages are: data collection, preprocessing, annotation/labeling, model selection, fine-tuning/training, evaluation/validation, and deployment/monitoring. Each stage ensures systematic domain adaptation.
What are the main risks of LLM fine-tuning?
Risks include bias, hallucinations, misuse, data privacy issues, and lack of transparency. Responsible AI practices and governance are crucial for mitigating these risks.
