
Vector Embeddings Explained: Semantic Search & LLM Integration Guide
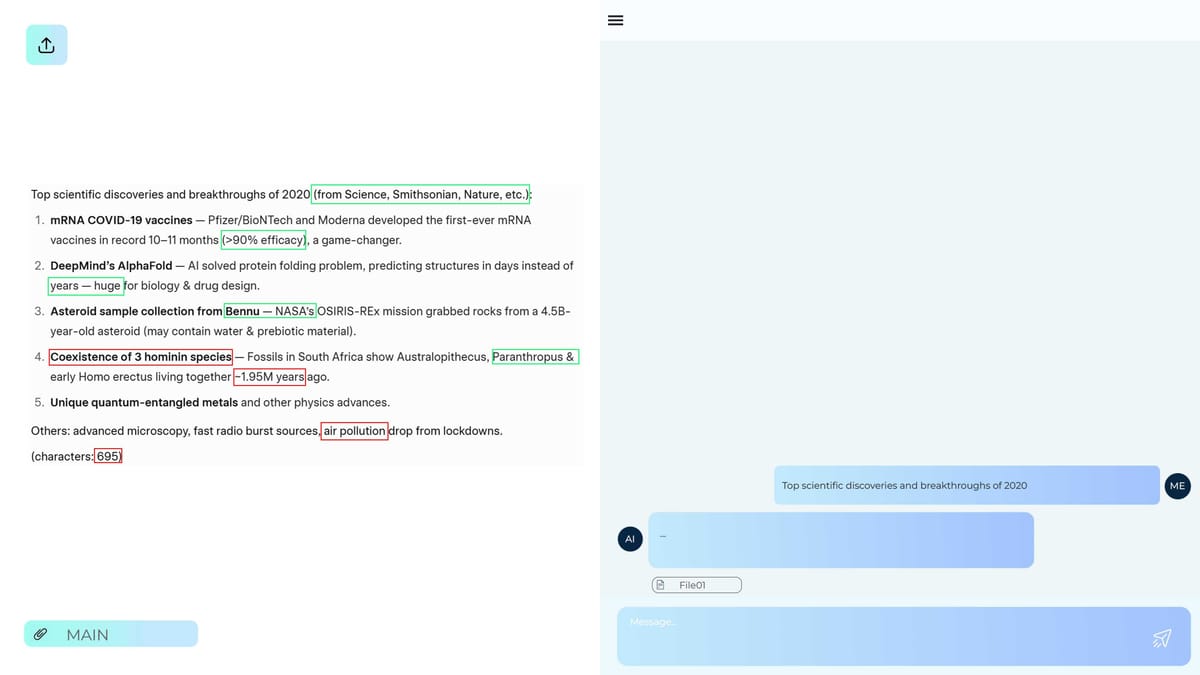
In modern search systems and large language models, semantic similarity embeddings play a key role, enabling computers to work not only with words but also with content. Thanks to text and word embeddings, text, documents, and queries are transformed into semantic vectors, in which the proximity between vectors reflects semantic similarity rather than the formal coincidence of words.
This idea is built on vector search - a mechanism that underlies semantic search, recommender systems, and data integration with LLM. Instead of searching for keywords, the system compares vectors to find the most relevant results, even when the query formulation differs significantly from the source text.

How vector embeddings represent meaning and how we compare them
Vector embeddings are numerical representations of data (usually text) in which the content is encoded as multidimensional vectors. Text embeddings and word embeddings transform words, sentences, or documents into semantic vectors, where each coordinate has no direct human meaning, but the entire set of coordinates reflects the semantics of the object.
Semantically close objects have vectors that are located close to each other in vector space. This is why the queries "cat" and "pet" may be closer to each other than "cat" and "car," even though the words are not the same.
Comparison of semantic vectors is usually performed using mathematical metrics. The most common of these is cosine similarity, which measures the angle between the vectors rather than their absolute length.
How the comparison works
- The text or query is converted into a set of text embeddings.
- The system calculates the similarity between the query vector and the database vectors.
- Using a metric (e.g., cosine similarity), the level of semantic similarity is determined.
- Vector search returns objects with the closest semantic vectors.
Models that create embeddings: pretrained, fine-tuned, and custom
Models for generating vector embeddings are trained to transform text into semantic vectors that preserve the semantic relationships between words and documents. Depending on the task and domain, pretrained, fine-tuned, or custom models are used.
Word embeddings typically operate at the level of individual words, while modern text embeddings model the context and meaning of entire text fragments, making them much more useful for search and integration with LLMs.
Vector embeddings across modalities
The principle of semantic similarity embeddings works for different modalities: images, audio, video, and structured data. In each case, the data is transformed into semantic vectors that reflect the object's content rather than its format or surface characteristics.
For text, text embeddings and word embeddings are used, which encode the meaning of words, sentences, and documents. For images, embeddings represent visual concepts — objects, scenes, and styles. Audio embeddings can convey language features, intonation, or acoustic patterns. Regardless of modality, objects with similar content will have similar semantic vectors.
Core applications: semantic search, recommendation systems, and beyond
Infrastructure basics: vector databases and approximate nearest neighbor search
To work effectively with vector embeddings, especially in semantic search tasks and multimodal systems, the right infrastructure is critical. The main components are vector databases and approximate nearest neighbor (ANN) search algorithms.
Vector databases
Vector databases are specialized repositories for semantic vectors. They are optimized for fast storage, indexing, and retrieval of text, word, and other vector embeddings. The key goal is to quickly find the closest vectors by content, i.e., those with high semantic similarity to the query. Features:
- Scaling to millions and billions of vectors.
- Support for vector search with different similarity metrics (cosine similarity, Euclidean distance).
- Integration with LLM for RAG architectures and semantic search.
Approximate nearest neighbor (ANN) search
Searching for the exact nearest vectors in a large space is very computationally expensive. ANN algorithms allow finding semantic vectors close to the query with high speed and low error.
Popular ANN methods:
- HNSW (Hierarchical Navigable Small World graphs) — graph structures for fast search.
- IVF (Inverted File Index) — partitioning space into clusters to speed up search.
- PQ (Product Quantization) — vector compression to save memory and speed up comparisons.
How it works together
- Data is converted into text embeddings or word embeddings, forming semantic vectors.
- A vector database stores these vectors and creates indexes for vector search.
- When a query is received, its vector is compared against the database using an ANN, enabling fast, efficient retrieval of the most relevant semantic vectors.
- The results can be used for semantic search, recommendations, or content preparation for LLM.
FAQ
What are vector embeddings?
Vector embeddings are numerical representations of data, such as text, images, or audio, in which semantic meaning is encoded as vectors. They allow machines to measure the semantic similarity between objects.
How do text embeddings differ from word embeddings?
Word embeddings represent individual words, while text embeddings capture the meaning of entire sentences or documents. Both produce semantic vectors for comparison in vector search.
What is semantic similarity in embeddings?
Embeddings' semantic similarity measures how close two semantic vectors are in meaning. It is used to find related words, sentences, or documents beyond exact word matches.
Why are vector databases important?
Vector databases efficiently store and index semantic vectors, enabling fast vector search across millions of embeddings. They are critical for scalable semantic search and LLM integration.
What is the approximate nearest neighbor (ANN) search?
ANN search finds vectors close to a query vector quickly without computing exact distances for all entries. It allows efficient retrieval of relevant semantic vectors for vector search applications.
What types of embedding models exist?
There are pretrained, fine-tuned, and custom models. Pretrained models work out of the box, fine-tuned models adapt to specific domains, and custom models are built from scratch for unique tasks.
How are embeddings used in recommendation systems?
Embeddings' semantic similarity enables systems to find items that match user preferences. Both text embeddings and word embeddings can be used to compare content for recommendations.
What are the main applications of vector embeddings?
They are used in semantic search, recommendation systems, clustering, multimodal applications, and LLM augmentation. Embeddings' semantic similarity enables these applications by representing data in a comparable vector space.
