Training LLMs for Code Generation: Data, Evaluation & Best Practices
In today’s AI world, large language models are becoming powerful tools not only for natural language processing but also for automatic code generation. The ability of models to deliver functional software solutions opens new horizons for developers, accelerating development, testing, and integration. However, the effectiveness of such models largely depends on the quality of training data, evaluation methods, and the application of best practices in their creation and use.
A comprehensive approach to preparing software code corpora that includes different programming languages, coding styles, and usage scenarios is important.
Key Takeaways
- Supervised fine-tuning (SFT) improves accuracy, readability, and security for coding tasks.
- APPS and HumanEval are essential benchmarks for measuring unit-test success and the effort required to repair them.
- PEFT/LoRA and QLoRA (NF4) enable fine-tuning on single-GPU setups.

Map user intent and success metrics for code generation LLM training
Building training data pipeline: sources, curation, and labeling
Dataset design for code LLMs: structure, chunking, and FIM
When designing code training data for an LLM that generates program code, it is important to properly structure and organize the programming dataset. Each dataset should include code spanning multiple programming languages, styles, and levels of complexity to ensure the model's universality. To assess the quality of data and models, it is useful to use standardized benchmarks, such as HumanEval or the MBPP benchmark, which allow for checking code correctness and the model's effectiveness on real programming tasks.
One key aspect is chunking, i.e., breaking large code files or projects into logical blocks. This allows the model to more easily assimilate the code structure, reduces the risk of losing context, and improves training performance. Chunks can be based on functions, classes, modules, or even logical segments of documentation and tests, which provides a more flexible representation of the data.
To improve training efficiency, FIM (Fill-in-the-Middle), an approach that allows the model to restore missing code fragments within existing blocks, is also used. Using FIM improves an LLM's ability to understand internal dependencies between lines of code and generate correct, functional output, which is especially important for code correctness on the HumanEval and MBPP benchmarks.
Model tuning and training stack with PEFT and quantization
The PEFT (Parameter-Efficient Fine-Tuning) approach allows you to adjust some model parameters while preserving the knowledge learned during previous training. For LLMs trained on code, this will be useful, as it allows you to quickly adapt the model to specific programming tasks or new languages without requiring a complete retraining of a large model.
Another key component is quantization, i.e., reducing the precision of model parameters without a significant loss of performance. Using quantization reduces memory requirements and speeds up inference, which is critical for large models working with large programming datasets. Combining PEFT with quantization enables high-performance, resource-efficient code generation.
The training stack for such models typically includes a pre-trained LLM, modules for processing code training data, a pipeline for evaluation on benchmarks such as HumanEval and the MBPP benchmark to assess code correctness, and optimization components such as PEFT and quantization to enable fast, efficient fine-tuning.
Hands-on configuration: from TrainingArguments to reproducibility
- Define TrainingArguments, including learning rate, batch size, number of epochs, and weight decay.
- Set seed values for reproducibility across PyTorch, NumPy, and random libraries.
- Enable gradient accumulation to handle large programming datasets on limited GPU memory.
- Configure logging and checkpointing to track training metrics and allow recovery.
- Apply mixed-precision (FP16) training to accelerate training and reduce memory usage.
- Use an evaluation strategy with metrics such as code correctness and pass rates on the HumanEval and MBPP benchmarks.
- Enable distributed training if multiple GPUs or nodes are available.
- Apply PEFT or other parameter-efficient fine-tuning methods to reduce training costs.
- Save model configuration, tokenizer, and training arguments for exact reproducibility.
- Document dataset splits, chunking, and preprocessing steps to ensure consistent results across runs.
Code generation LLM training with SFT
Training LLMs for code generation using SFT (Supervised Fine-Tuning) is a fundamental approach to achieving high accuracy and robustness in models for practical programming problems. In this process, the model first learns from a large code training dataset that spans different programming languages, coding styles, and complexity levels. Then, fine-tuning occurs on specialized programming datasets, where each example consists of an input description of the problem and its corresponding correct solution.
One key aspect of SFT is the use of well-annotated datasets to verify code correctness. To assess the quality of the generated code, standardized benchmarks such as HumanEval and the MBPP benchmark are often used to verify that the model produces functionally correct solutions and adheres to expected behavior.
SFT also enables adapting large language models to specific domains or projects, reducing the risk of errors and improving code-generation efficiency. During training, it is important to control the training parameters, ensure appropriate data chunking, and apply validation on test sets to maintain a high level of code correctness.
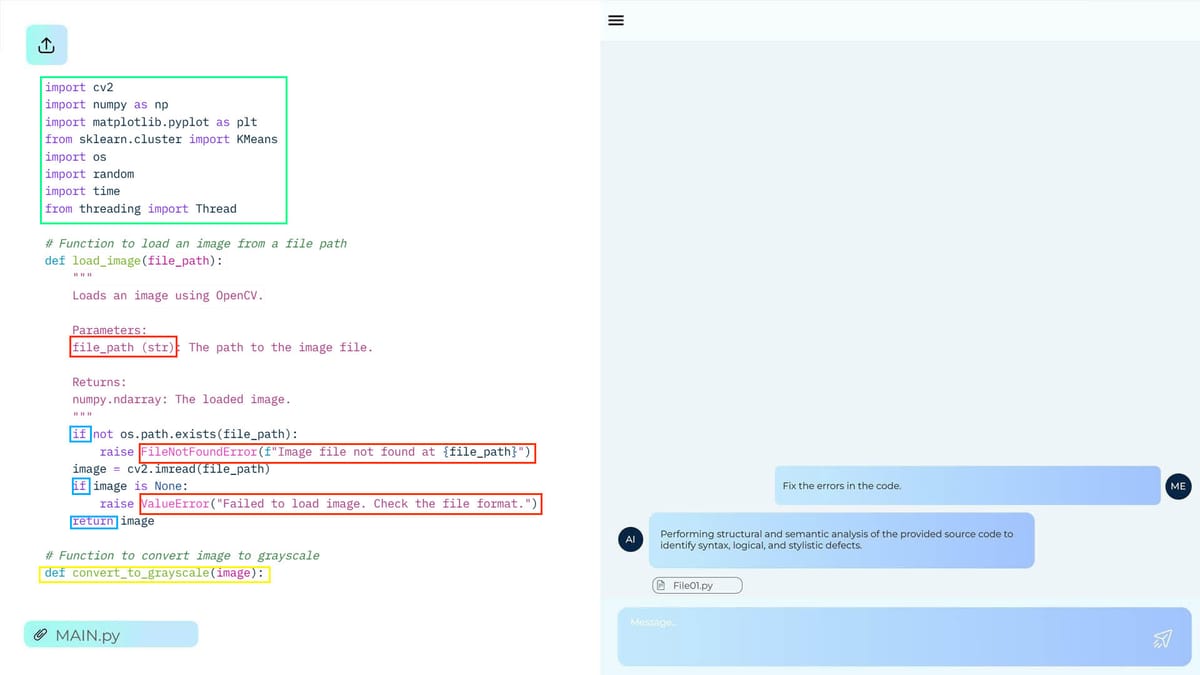
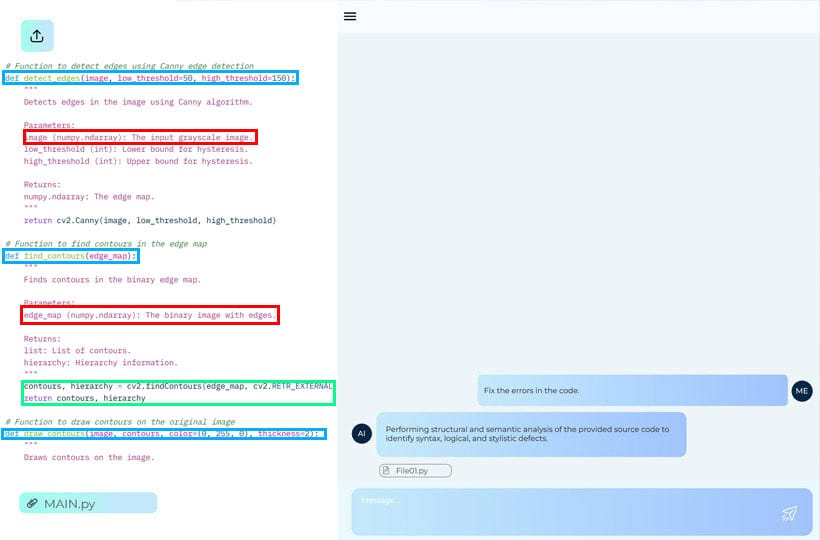
Where LLMs fail when generating code: common semantic and syntactic errors
Prompt and instruction design for coding tasks
Using RLHF, DPO, and RAG for stronger coding performance
- RLHF (Reinforcement Learning from Human Feedback) – learning through reinforcement based on human feedback; the model receives a score for the quality of the generated code and adjusts the generation to increase code correctness and compliance with best practices.
- DPO (Direct Preference Optimization) – direct optimization of preferences; the model learns to prefer more correct or desirable code variants based on pairwise comparisons with a programming dataset, without the need for complex reward models.
- RAG (Retrieval-Augmented Generation) – generation using retrieval; during code generation, the model refers to external sources, such as code training data or examples from repositories, to improve the accuracy, functionality, and consistency of the results.
FAQ
What is the role of code training data in LLMs for code generation?
Code training data provides examples of real programming tasks that the model learns from. High-quality datasets enhance code correctness and generalization across multiple programming languages.
Why is dataset curation important for programming datasets?
Curation ensures removal of duplicates, low-quality code, and sensitive information while standardizing formatting. This improves model learning efficiency and reduces errors during code generation.
What is chunking, and why is it applied in code LLMs?
Chunking divides large code files into logical segments, such as functions or classes. It allows the model to maintain context and generate syntactically and semantically correct code.
What benefits does FIM (Fill-in-the-Middle) provide for code generation?
FIM trains the model to complete missing segments within existing code blocks. This approach improves code correctness by teaching the model internal dependencies and partial code completion.
What is the purpose of SFT (Supervised Fine-Tuning) in code LLMs?
SFT adapts pretrained LLMs to task-specific programming datasets using input-output examples. It enables the model to generate functional code that passes benchmarks such as HumanEval and the MBPP benchmark.
In what way do prompts and instructions influence code generation?
Well-structured prompts clarify the task, provide input-output examples, and specify constraints. They guide the model to produce code that is syntactically correct and meets code correctness standards.
Which types of failures are common when LLMs generate code?
LLMs often produce syntax errors, incorrect logic, incomplete implementations, or dependency issues. Evaluating outputs on curated programming datasets and standardized benchmarks helps identify and mitigate these errors.
What advantages do PEFT and quantization offer for training code LLMs?
PEFT fine-tunes only a subset of model parameters, and quantization reduces memory requirements. Together, they enable efficient training on large programming datasets while maintaining high code correctness.
What contributions do RLHF, DPO, and RAG make to coding performance?
RLHF aligns outputs with human preferences, DPO optimizes for preferred code choices, and RAG incorporates relevant retrieved code examples. These methods collectively enhance functional accuracy and code correctness in real-world coding tasks.
Why are benchmarks like HumanEval and MBPP essential for evaluation?
They provide standardized tests to measure model performance and code correctness. Using these benchmarks ensures that LLMs generalize effectively across diverse programming datasets and practical coding tasks.