
Agent Training Data: A Guide to LLM-Based Agent Training
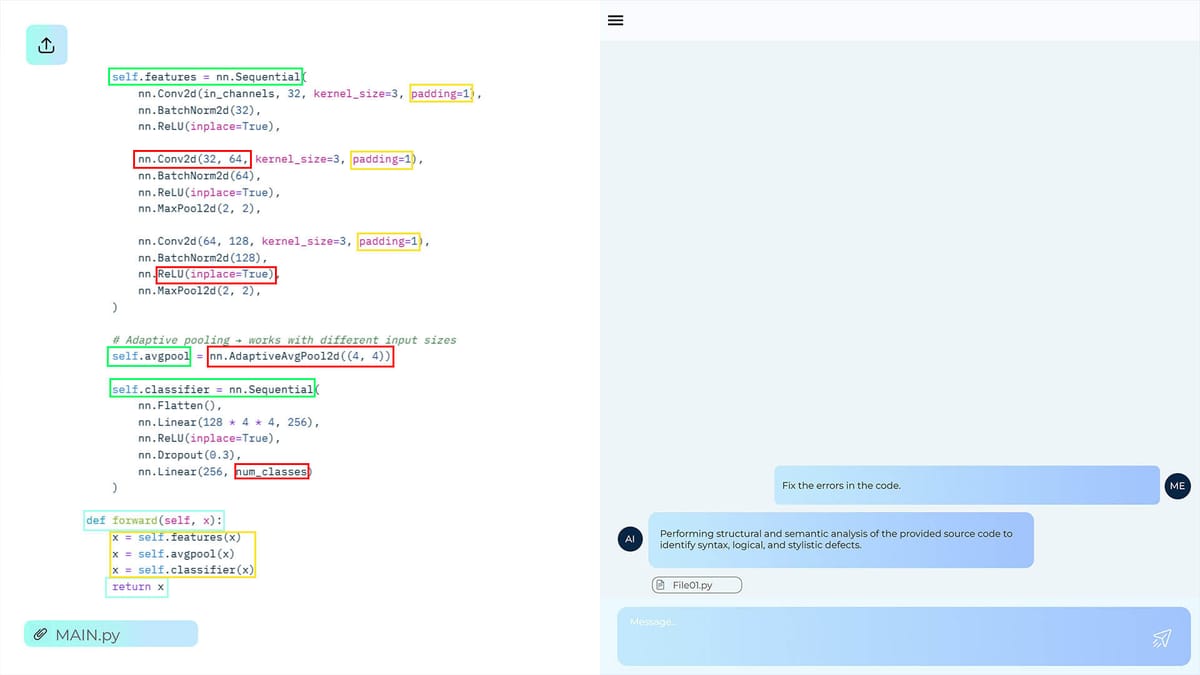
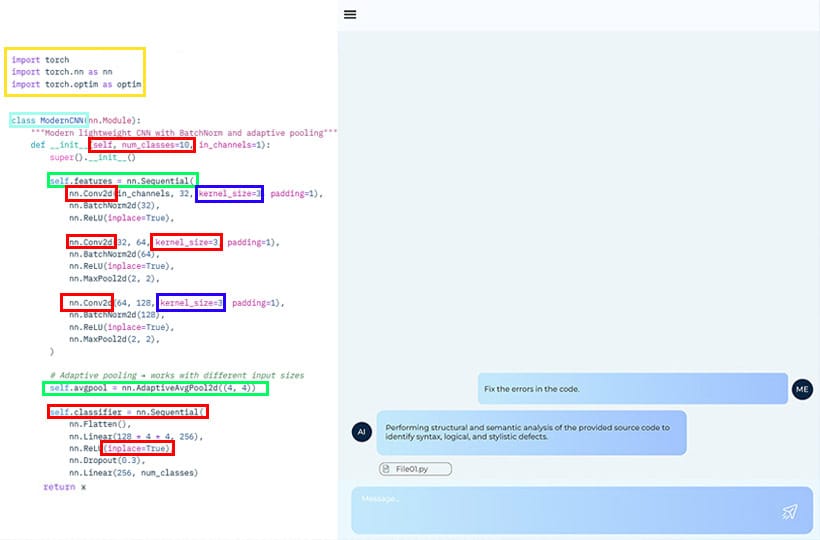
Agents based on Big Language Models (LLMs) are now changing the way businesses, researchers, and developers interact with data and make decisions. The success of these agents depends on the model architecture, quality, diversity, and management of the training data.
This guide provides an overview of the sources, generation methods, curation strategies, and practices for data preparation. This allows LLM-based agents to operate safely and effectively in real-world environments.
Quick Take
- Quality input data ensures reliable results.
- To connect datasets to measurable tasks, operational roles need to be defined.
- Blended strategies help strike a balance between speed, security, and scale.
- Methods improve efficiency, reduce evaluation time, and control costs.
- Human feedback and explanatory information minimize production risk.

Agent training data
Training LLM agents depends on the quality and provenance of the training data for agents. Agents learn to perceive context, plan actions, interact with the environment, and make decisions. Therefore, the data for them must cover real-world scenarios, synthetic interactions, and be carefully curated.
Data quality and representativeness
For LLM agents, quality data is data that has logic and thought patterns that they internalize.
Quality measurements:
- Accuracy. The data reflects real facts, events, or correct decisions.
- Completeness. There are no gaps in scenarios, roles, or contexts.
- Timeliness. The data is relevant to current conditions, rules, and policies.
- Consistency. There are no logical contradictions between sources.
- Noise vs. Signal. Useful information dominates over random or irrelevant samples.
Data representativeness
Representativeness means that the data accurately reflect the real distribution of the environment in which the agent operates. Let's consider the main aspects of representativeness:
- Scenario coverage. There are typical and rare cases in the data.
- Balance of roles and contexts. Different types of users, languages, and interaction styles.
- Distribution of actions and decisions. Not only "successful" or "ideal" cases.
- Correspondence to the environment. The data corresponds to the real conditions of use.
So, quality determines how correctly the agent thinks, representative of how widely it is ready to act.
Labeling and feedback
Labeling is the process of assigning a structured meaning to data that an agent can use to learn not only responses, but also behaviors and decisions. Unlike classical models, agents need multi-level annotations:
- Goal — what the agent needs to achieve
- State — the context in which the decision is made
- Action — a specific step or tool call
- Outcome — the consequence of the action
- Quality of the decision — correct/acceptable/incorrect
- Rationale — why this decision is correct or not
Labeling is performed by domain experts from various fields, trained annotators, or other models (such as auto-labeling with verification).
Feedback
Feedback is a signal that the agent receives after an action and uses it to correct its behavior. By collecting preference data from human evaluators, such as ranking outputs or providing feedback. Agents can learn which actions or responses are preferred, further improving performance and alignment.
Types of feedback:
Choosing a training approach
There are different approaches to training agents and LLMs that define how the model acquires knowledge and forms behavior. Each method has its own advantages, limitations, and optimal application scenarios. The choice of approach depends on data availability, task complexity, and the requirements for security and accuracy.
Platforms and tools for training agents
Agent platforms can be categorized based on functionality and intended use:
Keymakr specializes in creating high-quality training data for artificial intelligence models, including computer vision and other machine learning applications. The company collects, annotates, verifies, and classifies data, combining human experience with automated validation. This approach ensures high-quality data. Its proprietary
Keylabs data annotation and management platform provides tools for machine labeling, project workflow management, team collaboration, and support for multiple data formats. These tools help organizations prepare consistent and scalable datasets needed to train LLMs and intelligent agents.
Testing and validation
Testing and validation are important stages in the LLM agent lifecycle. The primary goal of these processes is to verify that the agent performs its functions correctly and safely before deploying it for interaction with real users.
The first stage of testing takes place in a sandbox environment. This is a controlled environment that simulates real conditions, but without risk to users. In the sandbox, the agent interacts with synthetic data, simulators or pre-created scenarios. This allows you to evaluate its behavior, reaction to edge-case situations, the correctness of its decisions, and compliance with established rules.
Such testing allows you to detect errors, hallucinations, biases, or unwanted behavior patterns at an early stage.
In the second stage, the agent interacts with real users, a process known as phased rollout or pilot testing. They start with a limited group or test scenarios. It enables you to evaluate the agent in real-world conditions, considering a range of requests, user patterns, and unpredictable contexts.
It is essential to collect user feedback, success metrics, and behavioral data to refine the agent and optimize its actions before a large-scale launch.
The combination of sandboxing and limited user testing allows you to achieve a balance between security and reliability. Without this approach, the agent may exhibit unwanted behavior in critical situations or provide incorrect answers, resulting in a loss of user trust and damage to the business's reputation.
Problems and practical solutions
When training and implementing LLM agents, recurring problems arise that can compromise the system's security for users. It is essential not only to identify these problems but also to develop practical solutions to address them.
FAQ
What sources of supervised and synthetic input data should be used?
Should real, labeled data and synthetically generated scenarios or simulations be used?
How to ensure the quality and representativeness of collections?
Quality and representativeness are ensured by carefully annotating, cleaning data, balancing scenarios, and verifying coverage of all relevant cases.
When is simulation learning better than reinforcement learning approaches?
Simulation learning is better when high-quality demonstrations of expert behavior are available, and strategies need to be quickly reproduced without lengthy trial-and-error.
What are the best practices for annotation and human-in-the-loop feedback?
It is best practice to combine expert labeling with automated validation, regularly assess quality, and provide structured feedback.
What testing and validation regime should precede deployment?
Before deployment, the agent should be sandbox-tested and then validated with a limited group of real users.
What are the common problems and pragmatic strategies to mitigate them?
Common problems include low-quality data, bias, model hallucinations, weak generalization, and deployment risks. Pragmatic strategies include data filtering and annotation, debiasing, RLHF, diverse training sets, sandbox testing, and gradual rollout.
