Image Processing Techniques: What Are Bounding Boxes?

Bounding boxes are one of the most popular—and recognized tools when it comes to image processing for image and video annotation projects.
Image processing techniques is one of the main reasons why computer vision continues to improve and drive innovative AI-based technologies. From self-driving cars to facial recognition technology—computer vision applications are the face of new image segmentation in image processing era.
But image detection and image annotation processing can’t be as simple as drawing rectangles around objects—right? How do bounding boxes work? What are the key elements that make this such a useful high level tool for annotators looking to create reliable datasets in real time?
Bounding Box Image Processing: What You Need to Know
A bounding box is an imaginary rectangle that serves as a point of reference for object detection and creates a collision box for that object in projects on image processing.
Data annotators draw these rectangles over machine learning images, outlining the object of interest within each image by defining its X and Y coordinates. This makes it easier for machine learning algorithms to find what they’re looking for, determine collision paths, and conserves valuable computing resources.
Bounding boxes or rotating bounding boxes are one of the most popular image annotation techniques in deep learning. Compared to other image segmentation processing methods, this method can reduce costs and increase annotation efficiency.
Using Bounding Boxes for Object Detection
But how does object detection work in relation to bounding boxes? How does this type of image annotation work? Answering this question requires looking at object detection as two components: object classification and object localization. In other words, to detect and target an object in an image, the artificial intelligence needs to know what it is and where it is during machine learning image processing.
Take self-driving cars as an example. An annotator will draw bounding boxes around other vehicles and label them. This helps train an algorithm of computer vision models to understand what vehicles look like. Annotating objects such as vehicles, traffic signals, and pedestrians makes it possible for autonomous vehicles to maneuver busy streets safely. Self-driving car perception models rely heavily on bounding boxes to make this possible.
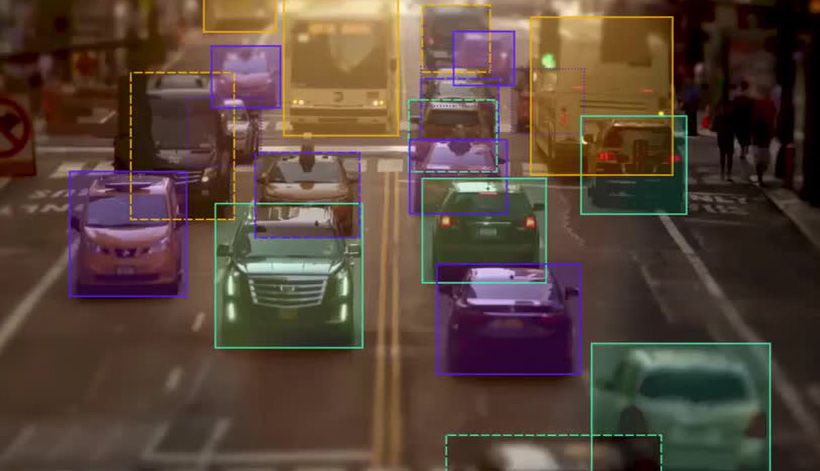
However, it’s important to note that a single bounding box doesn’t guarantee a perfect high level prediction rate. Enhanced object detection requires many bounding boxes in combination with data augmentation techniques.
Common Use Cases for Bounding Boxes
There are a variety of use cases for image processing and bounding boxes. Some of the more popular ones include:
- Self-driving cars
- Insurance claims
- Ecommerce
- Agriculture
- Healthcare
Bounding boxes are used in all of these areas as basic image annotation tool. It is used to train algorithms to identify patterns. An insurance company may leverage machine learning and training data to document insurance claims for car accidents, while an agriculture company could use it to identify what stage of growth a plant is in.

Professional Bounding Box Annotation Services
For those of us working in the AI industry, you may be familiar with the phrase “garbage in, garbage out.” This is spot-on. Feeding your system inaccurate training datasets is one of the best ways to sabotage your segmentation techniques and next computer vision project.
Misaligned bounding boxes throw a wrench in your algorithm and can take significant time to diagnose and fix. That’s why AI companies often choose to outsource image and video annotation to professional annotators. Artificial intelligence learns from us. Don’t teach it the wrong lessons with the wrong sementation algorithm. Rely on video and image annotation solutions that work.
Access the right tools, image processing techniques and segmentation algorithms with Keymakr expert annotators. We offer affordable image- and video-based high level training datasets delivered on time for your next machine learning project.