
Exploring the Top Algorithms for Semantic Segmentation
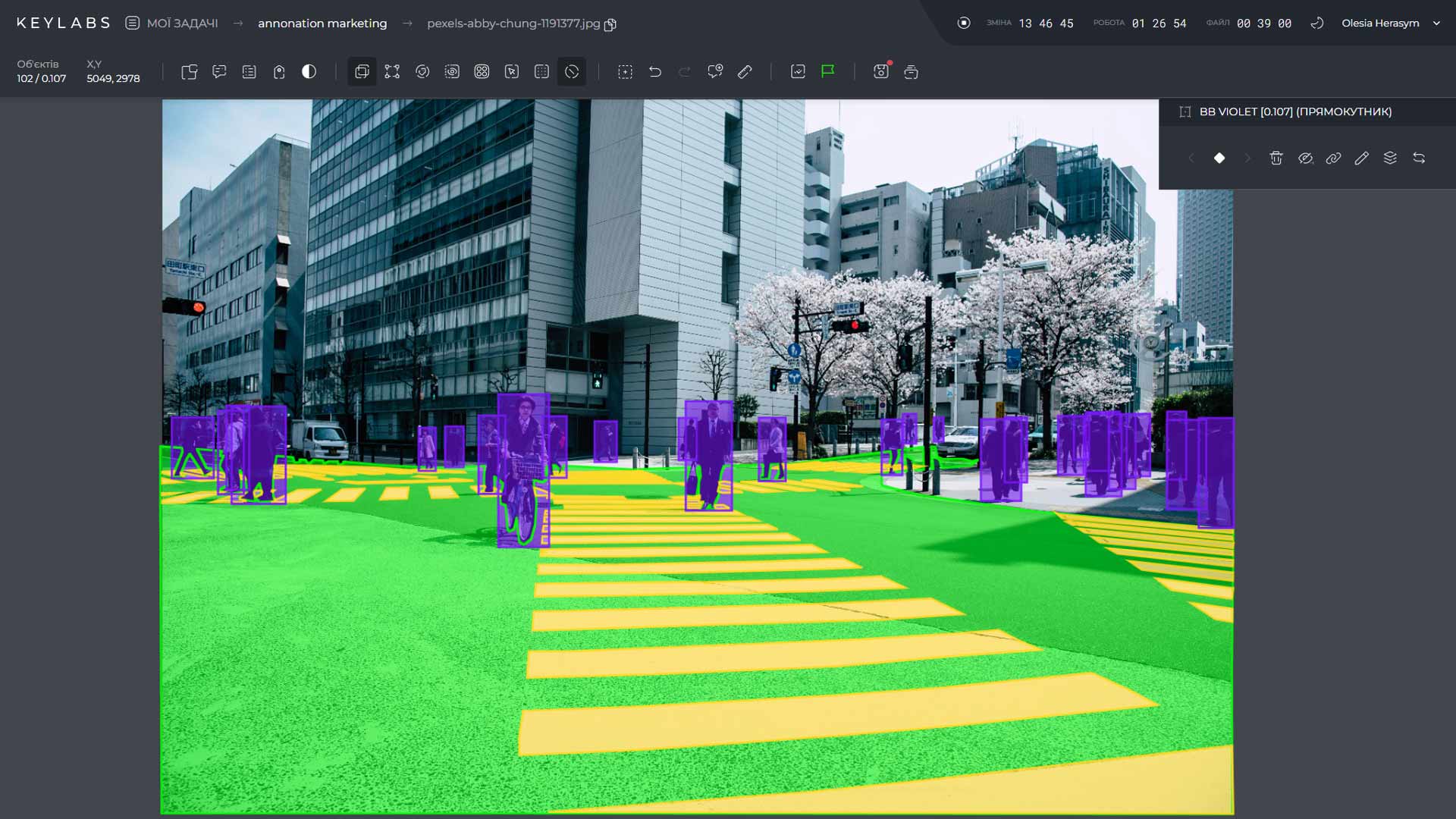
Semantic segmentation is a complex task in the field of computer vision that involves accurately identifying and labeling objects in an image at the pixel level. This process goes beyond simple image segmentation by providing detailed information about the objects present. Various algorithms and techniques are used for semantic segmentation, including both traditional methods and deep learning approaches. In this article, we will delve into the top algorithms for semantic segmentation and explore their applications in image analysis and object recognition.
Key Takeaways:
- Semantic segmentation is a process of classifying and labeling every pixel in an image.
- Traditional methods for semantic segmentation involve feature extraction and pixel classification.
- Deep learning methods, such as convolutional neural networks, have revolutionized semantic segmentation.
- Improvements in semantic segmentation algorithms aim to enhance accuracy and efficiency.
- Data augmentation techniques contribute to better model performance and segmentation accuracy.

What is Semantic Segmentation?
Semantic segmentation is a crucial process in computer vision that goes beyond simple image segmentation. It involves classifying and labeling every pixel in an image into different categories or objects, providing more detailed information about the objects present.
This technique plays a vital role in enabling machines to understand and interpret visual data accurately. By assigning labels to each pixel, semantic segmentation allows for object labeling and pixel-level classification, making it a powerful tool in various applications.
"Semantic segmentation is a fundamental task in computer vision, enabling machines to perceive and analyze visual information with a high level of detail."
By accurately delineating the boundaries of objects and assigning meaningful labels to pixels, semantic segmentation provides valuable insights for image analysis and object recognition. This technique is widely used in fields such as autonomous driving, robotics, medical imaging, and transport facility planning and management.
Object Labeling and Pixel-Level Classification
Semantic segmentation goes beyond traditional image segmentation techniques, which generally divide an image into regions or boundaries. Instead, it focuses on identifying and classifying each pixel based on the object or category it belongs to.
This pixel-level classification allows for more precise object labeling, enabling machines to distinguish between different objects or categories within an image. It facilitates accurate understanding and interpretation of complex visual scenes, making it an invaluable tool in computer vision applications.
Traditional Semantic Segmentation Methods
Traditional semantic segmentation methods involve two main processes: feature extraction and pixel classification. Feature extraction aims to extract relevant information from the image, identifying visual patterns and unique characteristics that can assist in distinguishing different objects and regions. This process helps in capturing the essential features required for accurate object recognition and pixel labeling.
Pixel classification is the subsequent step, where each pixel in the image is assigned a specific label based on its visual features extracted in the previous step. This process utilizes machine learning algorithms to classify pixels into different semantic categories, enabling accurate segmentation of objects in the image.
Support Vector Machine (SVM) Random Forest (RF) pixel classification traditional semantic segmentation methods segmentation accuracy
Support Vector Machine (SVM)
Support Vector Machine (SVM) is a supervised machine learning algorithm used for classification tasks. In the context of semantic segmentation, SVM analyzes the extracted visual features and learns to classify each pixel into different semantic categories. SVM constructs a hyperplane that maximally separates different classes, enabling accurate pixel labeling. However, SVM's performance heavily relies on the quality of the extracted features and the appropriate selection of hyperparameters.
Random Forest (RF)
Random Forest (RF) is an ensemble learning method that combines multiple decision trees for classification. In semantic segmentation, RF uses a collection of decision trees to classify pixels based on their extracted visual features. The randomness introduced by Random Forest reduces overfitting and improves the generalization ability of the model. However, RF may face challenges in handling complex semantic structures and preserving fine-grained details in the segmentation process.
Although traditional semantic segmentation methods using SVM and RF have been widely employed in the past, they are typically outperformed by deep learning-based methods in terms of accuracy and efficiency. The limitations of traditional algorithms have led to the surge of interest in leveraging deep learning techniques for semantic segmentation.
| Traditional Semantic Segmentation Methods | Pros | Cons |
|---|---|---|
| Support Vector Machine (SVM) | - Effective for linearly separable data | - Relies on feature extraction quality - Sensitive to parameter selection |
| Random Forest (RF) | - Robust against overfitting | - Difficulty handling complex structures - May lose fine-grained details |
Deep Learning Methods for Semantic Segmentation
Deep learning methods have revolutionized the field of semantic segmentation by achieving higher accuracy and efficiency. These methods leverage the power of convolutional neural networks (CNNs), which have proven to be highly effective in image processing tasks.
One of the popular deep learning models for semantic segmentation is the Fully Convolutional Network (FCN). FCN extends CNN architectures to perform pixel-level classification, enabling accurate object segmentation in images.
Another widely used model is U-Net, which combines the benefits of FCN with skip connections. This architecture allows for feature extraction at different resolutions and helps preserve finer details during the segmentation process.
DeepLab is another deep learning-based semantic segmentation model that utilizes atrous convolution to capture multi-scale information effectively. It employs dilated convolutions for dense feature extraction while maintaining contextual information.
PSPNet (Pyramid Scene Parsing Network) is a deep learning model that adopts a pyramid pooling module to capture contextual information at multiple scales. This multi-scale feature representation improves the accuracy of semantic segmentation in images with objects of varying sizes.
Comparison of Deep Learning Models for Semantic Segmentation
| Model | Description |
|---|---|
| FCN | Fully Convolutional Network architecture for pixel-level classification. |
| U-Net | Combines FCN with skip connections for accurate segmentation while preserving finer details. |
| DeepLab | Utilizes atrous convolution to capture multi-scale information effectively. |
| PSPNet | Adopts a pyramid pooling module for improved contextual information at multiple scales. |
These deep learning models have significantly advanced the field of semantic segmentation, enabling more accurate and precise object identification and labeling. By leveraging the power of convolutional neural networks, these models have overcome many limitations of traditional methods and provided a foundation for further advancements in semantic segmentation algorithms.

Improvements and Advancements in Semantic Segmentation Algorithms
Researchers in the field of computer vision are constantly striving to enhance the precision and accuracy of semantic segmentation algorithms. These advancements focus on various aspects, including feature extraction, performance optimization, and module structure optimization. By improving these key areas, researchers are pushing the boundaries of semantic segmentation capabilities, paving the way for more advanced applications and analyses.
Enhancements in Feature Extraction
One area of improvement in semantic segmentation algorithms is feature extraction. Feature extraction involves identifying and extracting relevant information from the input image to facilitate accurate object recognition and scene understanding. Recent advancements have focused on developing more sophisticated techniques to extract robust features that capture the subtle characteristics of objects in varying environmental conditions.
Performance Optimization
Another important aspect of improving semantic segmentation algorithms is performance optimization. Researchers aim to make these algorithms more efficient and computationally lightweight, enabling real-time segmentation on resource-constrained devices. Performance optimization techniques include algorithmic optimizations, parallel computing strategies, and hardware acceleration using specialized processors like GPUs (Graphics Processing Units).
Module Structure Optimization
The module structure of semantic segmentation algorithms plays a crucial role in their performance and efficiency. Researchers are continually optimizing the architecture of these modules to improve the overall segmentation quality. This includes exploring novel encoder-decoder structures, integrating skip connections, and enhancing feature fusion methods to achieve more accurate and consistent object delineation.
“The advancements in feature extraction, performance optimization, and module structure optimization have greatly contributed to the overall progress in semantic segmentation algorithms. These improvements open up new possibilities for applications such as autonomous driving, robotics, and medical imaging, where precise object identification is of utmost importance.”
Researchers have made significant strides in enhancing the capabilities of semantic segmentation algorithms by focusing on feature extraction, performance optimization, and module structure optimization. The advancements in these areas have paved the way for improved object recognition, scene understanding, and image analysis in various domains.
| Enhancement | Description |
|---|---|
| Expanded to 3D Images | Algorithms capable of handling three-dimensional images have been developed, enabling advanced segmentation in volumetric data such as medical scans and point clouds. |
| Improved Feature Fusion | Researchers have devised more effective methods for fusing multi-scale features, allowing algorithms to capture fine-grained details while maintaining contextual information. |
| Optimized Loss Functions | Loss functions have been tailored to better address semantic segmentation challenges, mitigating common issues like class imbalance and handling large intra-class variability. |
| Enhanced Encoder-Decoder Structure | Researchers have introduced novel encoder-decoder architectures that leverage the strengths of both components, resulting in improved object boundary localization and semantic feature extraction. |
The ongoing advancements in semantic segmentation algorithms continue to drive progress in the field of computer vision. These improvements empower machines with better object recognition capabilities and enable a wide range of applications, from autonomous vehicles navigating complex environments to medical imaging systems aiding accurate diagnosis and treatment planning.
Data Augmentation for Semantic Segmentation
Data augmentation is a crucial technique that significantly enhances the performance of semantic segmentation models. It tackles challenges such as limited training samples and imbalanced datasets by generating additional data that closely resembles real-world scenarios.
One effective approach to data augmentation is virtual data augmentation. In this method, existing images are modified using semantic segmentation techniques to generate new virtual data. By applying semantic segmentation to existing images, the model learns to capture intricate details and accurately label pixels, leading to improved segmentation accuracy.
| Data Augmentation Techniques | Benefits |
|---|---|
| Rotation and Flip | Helps the model generalize to different orientations and viewpoints. |
| Scaling and Cropping | Enables the model to handle objects of varying sizes and focus on relevant regions. |
| Translation and Shearing | Enhances the model's robustness to object position and deformations. |
| Color Jittering | Improves the model's ability to handle variations in lighting and color conditions. |
By incorporating virtual data augmentation into the training process, the model learns to generalize better and becomes more robust to variations in real-world data. This, in turn, leads to improved model performance and segmentation accuracy.
One notable network architecture that has benefited from data augmentation is the U-Net network. The U-Net architecture, a popular choice for semantic segmentation tasks, combines both downsampling (encoder) and upsampling (decoder) pathways to capture both local and global context. By training the U-Net network with augmented data, researchers have observed enhanced segmentation accuracy and better generalization capabilities.
Through data augmentation and the utilization of advanced network architectures like the U-Net, researchers continue to push the boundaries of semantic segmentation. By improving the robustness and performance of the models, data augmentation techniques are paving the way for more accurate and reliable segmentation results in a wide range of applications.
Applications of Semantic Segmentation
Semantic segmentation, with its ability to accurately identify and label objects at the pixel level, finds diverse applications in various fields. By leveraging the power of semantic segmentation algorithms, industries such as autonomous driving, robotics, medical imaging, and transport facility planning and management are benefiting from advanced computer vision capabilities.
Semantic Segmentation in Autonomous Driving
The application of semantic segmentation in autonomous driving is paramount in enabling vehicles to navigate safely and effectively in complex environments. By understanding and interpreting the surrounding environment, vehicles can make informed decisions regarding path planning and obstacle avoidance. Semantic segmentation allows for real-time detection and classification of objects such as pedestrians, vehicles, traffic signs, and road markings, enhancing the overall safety and efficiency of autonomous driving systems.
Semantic Segmentation in Robotics
In the field of robotics, semantic segmentation enables robots to perceive and interact with objects accurately. By segmenting the scene, robots can understand object boundaries, shapes, and spatial relationships. This knowledge facilitates object manipulation, grasping, and navigation, thereby enhancing the overall performance and intelligence of robotic systems. Semantic segmentation plays a vital role in applications such as object recognition, localization, and mapping, leading to advancements in industries such as manufacturing, healthcare, and logistics.
Semantic Segmentation in Medical Imaging
Medical imaging heavily relies on semantic segmentation for precise diagnosis and treatment planning. By accurately segmenting anatomical structures and pathological areas in medical images, clinicians can gain valuable insights and aids in disease detection, monitoring, and surgical interventions. Semantic segmentation assists in identifying organs, tumors, lesions, and other abnormalities, enabling healthcare professionals to provide targeted therapies and personalized medical care.
Semantic Segmentation in Transport Facility Planning and Management
Semantic segmentation plays a crucial role in transport facility planning and management by allowing for accurate monitoring of land cover changes and environmental impacts. By segmenting satellite or aerial imagery, urban planners and environmental managers can assess land use patterns, monitor vegetation growth, analyze infrastructure development, and evaluate the ecological impact of transportation systems. This information aids in making informed decisions about urban planning, resource allocation, and sustainable development initiatives.
| Application | Benefits |
|---|---|
| Autonomous Driving | Safer navigation, obstacle detection and avoidance |
| Robotics | Precise object perception and interaction |
| Medical Imaging | Precise diagnosis and treatment planning |
| Transport Facility Planning and Management | Accurate monitoring of land cover changes and environmental impacts |
Through its wide range of applications, semantic segmentation continues to push the boundaries of computer vision technology, unlocking new possibilities and enabling innovative solutions across industries.
Future Directions for Semantic Segmentation Research
The field of semantic segmentation is continuously evolving, with researchers exploring various future directions to enhance the capabilities of this computer vision technique. One promising area of focus is the development of advanced computer vision solutions for transport facility planning and management.
Transport facility planning and management involve the efficient utilization of resources, effective monitoring of transportation networks, and accurate assessment of land cover changes. To achieve these goals, advanced computer vision solutions can be leveraged to provide real-time monitoring and assessment of transportation infrastructure, such as roads, railways, and airports. These solutions can help analyze traffic patterns, identify bottlenecks, and optimize transportation systems for improved efficiency.
Moreover, by integrating semantic segmentation algorithms with remote sensing and geospatial data, transport facility planners and managers can obtain valuable insights into land cover changes and environmental impacts. This information can aid in making informed decisions regarding infrastructure development, environmental conservation, and sustainable transportation planning.
Another important future research direction in semantic segmentation is the continuous improvement of algorithm efficiency and accuracy. Researchers are working on developing algorithms that can handle complex images with higher precision and faster processing times. By optimizing feature extraction techniques, refining model architectures, and exploring novel loss functions, semantic segmentation algorithms can deliver more accurate and reliable results, enabling better decision-making in various applications.
Furthermore, exploring new applications of semantic segmentation in different industries is another avenue for future research. While semantic segmentation has already found applications in diverse fields such as autonomous driving, robotics, and medical imaging, there is still tremendous potential to expand its use cases. Industries like agriculture, urban planning, and retail can benefit from the precise object labeling and classification capabilities of semantic segmentation algorithms.
Lastly, addressing challenges such as data scarcity and model interpretability is a crucial aspect of future semantic segmentation research. Collecting large-scale annotated datasets remains a challenge, especially for specific domains or rare objects. Developing techniques for training semantic segmentation models with limited data will enable wider adoption of the technology across various industries. Additionally, ensuring transparency and interpretability of the underlying models will enhance trust and enable stakeholders to understand and validate the segmentation results.
In conclusion, future directions for semantic segmentation research encompass the development of advanced computer vision solutions for transport facility planning and management, the continuous improvement of algorithm efficiency and accuracy, exploring new industry-specific applications, and addressing challenges related to data scarcity and model interpretability. By pushing the boundaries of semantic segmentation, researchers and practitioners can unlock the full potential of this powerful computer vision technique.

Conclusion
In conclusion, the advancement and application of semantic segmentation algorithms have transformed the fields of image analysis and object recognition. These algorithms have empowered machines to accurately understand and interpret visual data, leading to groundbreaking advancements in various industries.
Both traditional methods and deep learning methods have been developed to tackle the complexities of semantic segmentation. However, deep learning methods, particularly convolutional neural networks, have proven to be more effective, achieving superior accuracy and efficiency in pixel-level classification.
Looking ahead, the future of semantic segmentation research holds exciting possibilities. Researchers aim to further enhance algorithm performance, explore new applications in diverse industries, and develop advanced computer vision solutions. These solutions will play a crucial role in transport facility planning and management, enabling real-time monitoring and assessment of land cover changes.
Overall, semantic segmentation remains a critical area of research and development in the field of computer vision. With continued advancements and research efforts, these algorithms will continue to pave the way for more intelligent and accurate image analysis and object recognition systems.
FAQ
What is semantic segmentation?
Semantic segmentation is a process in computer vision that involves accurately identifying and labeling objects in an image at the pixel level. It goes beyond simple image segmentation by providing more detailed information about the objects in the image.
What are the traditional methods for semantic segmentation?
Traditional semantic segmentation methods involve two main processes: feature extraction and pixel classification. Feature extraction aims to extract relevant information from the image, while pixel classification assigns labels to each pixel based on its visual features.
What are some deep learning methods for semantic segmentation?
Some popular deep learning models for semantic segmentation include Fully Convolutional Network (FCN), U-Net, DeepLab, and PSPNet. These models leverage the power of convolutional neural networks (CNNs) to extract features and classify pixels in complex images accurately.
What are some improvements in semantic segmentation algorithms?
Researchers have made improvements in semantic segmentation algorithms by expanding from 2D to 3D images, improving feature fusion methods, optimizing loss functions, and enhancing the encoder-decoder structure. These advancements aim to enhance the precision and accuracy of semantic segmentation algorithms.
How does data augmentation improve semantic segmentation models?
Data augmentation plays a crucial role in improving the performance of semantic segmentation models. One effective approach is virtual data augmentation, where semantic segmentation is applied to existing images to generate new virtual data. This method increases the number of training samples and improves model performance and segmentation accuracy.
What are some applications of semantic segmentation?
Semantic segmentation has a wide range of applications in autonomous driving, robotics, medical imaging, and transport facility planning and management. It enables vehicles to understand the surrounding environment, robots to perceive and interact with objects, assists in precise medical diagnosis, and allows for accurate monitoring of land cover changes and environmental impacts.
What are some future research directions for semantic segmentation?
Future research directions include the development of advanced computer vision solutions for transport facility planning and management, improving the efficiency and accuracy of semantic segmentation algorithms, exploring new applications in different industries, and addressing challenges such as data scarcity and model interpretability.



