
Deep Learning Techniques in Semantic Segmentation Explained
Semantic segmentation using deep learning algorithms is revolutionizing the field of image processing and computer vision. With the rise of artificial intelligence and machine learning, convolutional neural networks (CNN) have emerged as powerful tools for accurate and efficient object detection and segmentation in images.
In semantic segmentation, each pixel in an image is assigned a specific label or category, allowing for precise classification and segmentation of objects. This technique plays a crucial role in various applications, from autonomous driving to medical imaging and industrial inspection.
Deep learning methods, such as Fully Convolutional Networks (FCN), U-net, Pyramid Scene Parsing Network (PSPNet), and DeepLab, are commonly used for semantic segmentation tasks. These methods employ convolutional neural networks to extract meaningful features and representations, enabling the accurate segmentation of objects within an image.
Key Takeaways:
- Deep learning algorithms have transformed semantic segmentation in computer vision.
- Convolutional neural networks (CNN) are widely used for accurate object detection and segmentation.
- Semantic segmentation involves assigning a label to every pixel in an image, enabling precise classification and segmentation.
- Popular deep learning methods for semantic segmentation include FCN, U-net, PSPNet, and DeepLab.
- These techniques have diverse applications, from autonomous driving to medical imaging and industrial inspection.

What is Semantic Segmentation?
Semantic segmentation is an essential technique in image processing and computer vision that involves classifying objects in an image, localizing their positions, and segmenting the pixels within those objects using a segmentation mask. Unlike other forms of image segmentation, such as instance segmentation, semantic segmentation focuses on pixel-level classification and separation of different image classes.
At its core, semantic segmentation is a three-step process. Firstly, it classifies objects within images, assigning each pixel to a specific category or class. Next, it localizes the objects by determining their positions and drawing bounding boxes around them. Finally, it creates a segmentation mask, which involves segmenting the pixels within the localized objects and distinguishing them from the rest of the image.
Semantic segmentation is a powerful technique that enables pixel-level classification in images, providing detailed information about the objects present. It is an essential tool in various fields, including autonomous driving, medical imaging, industrial inspection, satellite imagery, and robotic vision.
To better understand semantic segmentation, consider an example scenario where an autonomous vehicle needs to identify and differentiate objects on the road. By performing semantic segmentation, the vehicle can precisely classify and localize pedestrians, cyclists, traffic signs, and other vehicles, allowing it to make accurate decisions and navigate safely.
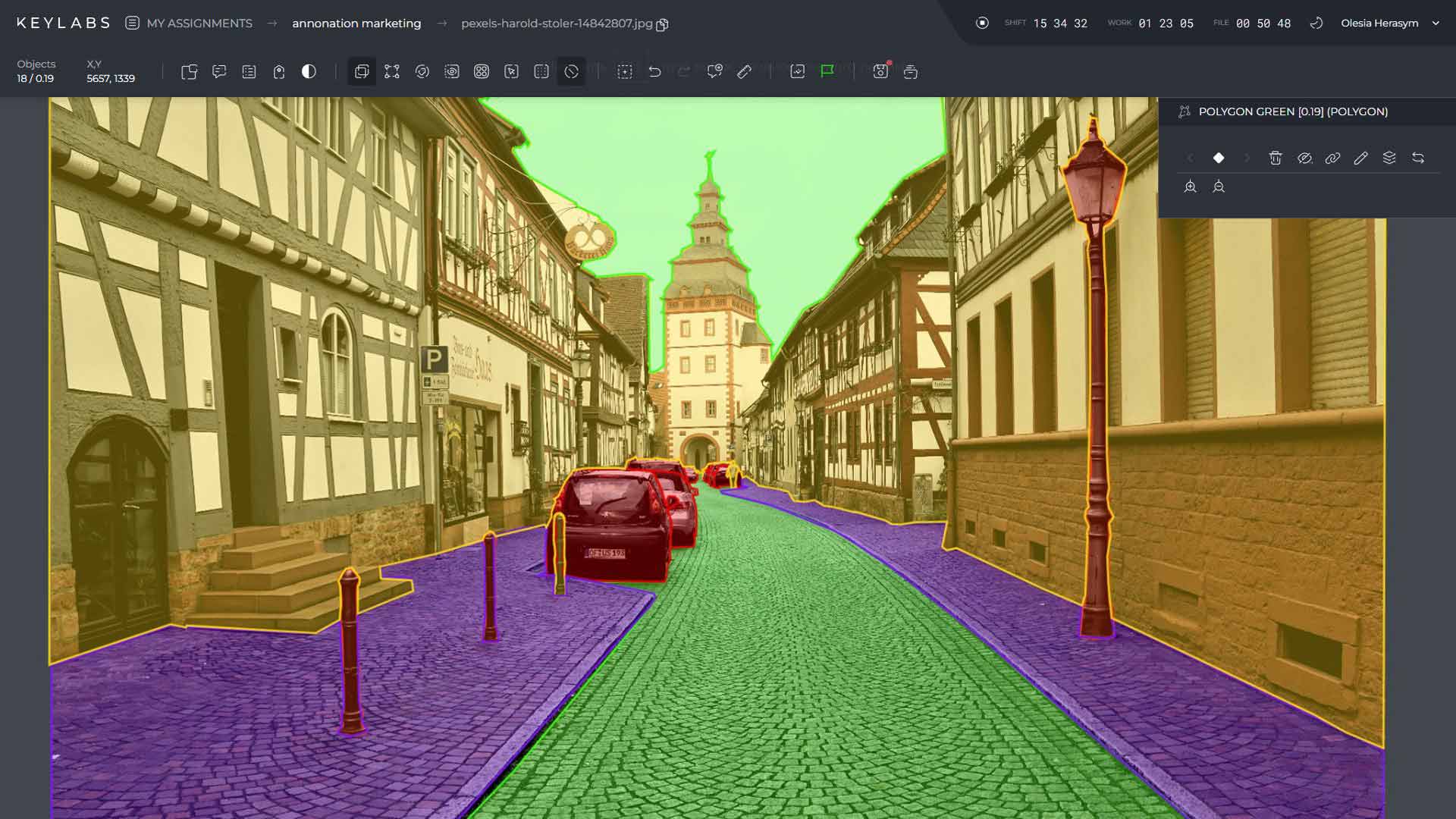
The image above depicts the output of a semantic segmentation model, where different objects are labeled and segmented based on their respective classes. This segmentation mask provides valuable information for further analysis and processing.
Overall, semantic segmentation plays a crucial role in various computer vision applications, providing accurate and detailed insights into image content at the pixel level. Through its classification, localization, and segmentation capabilities, semantic segmentation enables advanced image analysis and understanding.
Semantic Segmentation Deep Learning Methods
Deep learning methods are widely used in the field of semantic segmentation, allowing for accurate and efficient image analysis. These methods leverage convolutional neural networks (CNN) to extract features and representations that enable precise pixel-level classification.
Among the various deep learning architectures utilized for semantic segmentation, some popular ones include:
Fully Convolutional Networks (FCN)
FCN performs semantic segmentation by employing an encoder-decoder structure. The encoder extracts high-level features from the input image, while the decoder upsamples the segmented image to its original resolution. This process allows for the preservation of spatial information and the generation of pixel-level predictions.
U-net
U-net is another widely used architecture for semantic segmentation. It employs an encoder-decoder structure with skip connections or shortcut connections. These connections address information loss that may occur during the encoding and decoding processes, leading to enhanced segmentation accuracy.
Pyramid Scene Parsing Network (PSPNet)
PSPNet utilizes a pyramid pooling module to capture global context information. By incorporating multi-scale features, PSPNet enhances the performance of semantic segmentation by considering a broader context and improving the understanding of object relationships within an image.
DeepLab
DeepLab integrates atrous (or dilated) convolution, which allows for the extraction of denser representation at multiple scales. This technique enhances the ability of the model to capture fine details and small objects, leading to improved segmentation results.
These deep learning methods, including FCN, U-net, PSPNet, and DeepLab, have shown excellent performance in various semantic segmentation tasks across different domains, such as computer vision, medical imaging, and autonomous driving. Their ability to extract meaningful features and rich representations has significantly contributed to advancing the field of semantic segmentation.
By employing these deep learning methods, researchers and practitioners can achieve accurate and precise semantic segmentation, paving the way for numerous applications in diverse industries.
Loss Functions
In the training process of deep learning models for semantic segmentation, loss functions play a critical role in optimization. These functions provide a measure of how well the model is performing and guide the training process towards finding the optimum parameters.
The most commonly used loss function for pixel-wise classification in semantic segmentation is the pixel-wise cross-entropy loss. This loss function calculates the discrepancy between the predicted class probabilities and the ground truth labels at a pixel level. It leverages the Softmax function to obtain the predicted probabilities and compares them to the true labels to quantify the loss.
Another loss function that can be employed for evaluating the similarity between the predicted and ground truth segmentation masks is the dice coefficient. The dice coefficient measures the overlap between two sets of pixels and provides a measure of how well the segmentation mask aligns with the ground truth.
"The use of loss functions is essential in training deep learning models for semantic segmentation as they guide the optimization process towards accurate pixel-level classification."
Real-world applications of Semantic Segmentation
Semantic segmentation, with its ability to classify and segment pixels in images, has found numerous real-world applications across industries. Let's explore how semantic segmentation is utilized in various fields:
Autonomous Driving
"Semantic segmentation plays a vital role in autonomous driving systems, enabling the identification of drivable paths, separation of road features from obstacles, and detection of pedestrians, traffic signs, and other vehicles. By accurately segmenting different elements in the environment, autonomous vehicles can make informed decisions and navigate safely on the road."
Medical Imaging
"In the field of medical imaging, semantic segmentation proves incredibly valuable for the analysis and detection of cancerous anomalies in cells. By segmenting and classifying various structures within medical images, doctors can gain precise insights into the presence and characteristics of tumors, aiding in diagnosis and treatment planning."
Industrial Inspection
"Semantic segmentation is extensively adopted in industrial inspection processes to identify and locate defects in materials. By segmenting different regions and analyzing the properties of materials, manufacturers can efficiently detect and address any potential flaws, ensuring the production of high-quality products."
Satellite Imagery
"The analysis of satellite imagery often relies on semantic segmentation to identify and classify terrain features such as mountains, rivers, and deserts. By accurately segmenting landforms, environmental researchers, and urban planners can gain valuable insights into geological and geographical characteristics."
Robotic Vision
"Semantic segmentation powers robotic vision systems, enabling them to identify and navigate objects and terrain effectively. By segmenting and classifying various elements in the environment, robots can make informed decisions and safely interact with their surroundings, supporting applications ranging from industrial automation to search and rescue operations."
In conclusion, semantic segmentation finds real-world applications in diverse industries such as autonomous driving, medical imaging, industrial inspection, satellite imagery, and robotic vision. By accurately segmenting and classifying pixels, semantic segmentation empowers intelligent systems to understand and interact with their environments, opening up new possibilities for innovation and problem-solving.
How to Perform Semantic Segmentation using MATLAB
MATLAB provides a comprehensive platform for performing semantic segmentation using deep learning. With its rich set of tools and functions, MATLAB enables researchers and practitioners to efficiently tackle image processing and computer vision tasks, including the precise identification and labeling of objects at the pixel level.
To perform semantic segmentation using MATLAB, the workflow typically involves several key steps:
- Data Labeling: This step entails either manually labeling the data or obtaining pre-labeled data. Accurate labeling is essential for training and evaluating the semantic segmentation model.
- Datastore Creation: Creating datastores for both the original images and their corresponding labeled images helps organize and manage the data. By setting up proper datastores, MATLAB ensures seamless data integration into the semantic segmentation workflow.
- Data Partitioning: Partitioning the datastores into training and testing sets is crucial for evaluating the model's performance. MATLAB provides tools for partitioning the data effectively and ensuring accurate validation.
- Convolutional Neural Network (CNN) Import and Modification: MATLAB allows for the importing of pre-trained CNN models, which can be modified to suit the semantic segmentation task at hand. One popular modified CNN architecture for semantic segmentation in MATLAB is SegNet.
- Training and Evaluation: After importing and modifying the CNN model, the next step entails training the model using the labeled images. MATLAB offers extensive support for training deep learning models and allows for evaluation using various performance metrics.
By following these steps in MATLAB, researchers and practitioners can effectively perform semantic segmentation on their image datasets using deep learning techniques. The flexibility and robustness of MATLAB's tools and functions enable efficient experimentation, fine-tuning, and evaluation of semantic segmentation models.n with Object Detection
When it comes to analyzing and understanding images, two commonly used techniques are semantic segmentation and object detection. While they share similarities, there are distinct differences that set them apart. This section will explore the comparison between semantic segmentation and object detection, highlighting the unique advantages of semantic segmentation.
Pixel-Level Classification and Precise Object Boundaries
Semantic segmentation involves pixel-level classification, allowing for accurate identification and labeling of individual pixels according to their class. This means that each pixel in an image is categorized, providing a level of detail that object detection alone cannot achieve. Semantic segmentation can precisely outline the boundaries and shapes of objects, even if they are irregular or complex.
"Semantic segmentation provides a granular understanding of the composition of an image, allowing for precise object localization and shape representation."
The Role of Bounding Boxes
In contrast, object detection relies on bounding boxes to identify and localize objects within an image. While bounding boxes are effective for determining the presence and general location of objects, they do not capture the finer details and structure of objects. Semantic segmentation goes beyond bounding boxes by providing a more comprehensive and detailed analysis of objects at the pixel level.
Precision and Detail
Semantic segmentation excels in providing precise and detailed information about objects in an image. By labeling individual pixels, semantic segmentation algorithms can accurately differentiate between objects of the same class. This level of precision allows for more accurate analysis and understanding of image content, enabling advanced applications such as autonomous driving, medical imaging, and robotic vision.
"Semantic segmentation offers a higher level of accuracy and detail compared to object detection, making it particularly useful in applications where capturing fine object boundaries and shapes is critical."
The Visual Appeal of Semantic Segmentation
To illustrate the capabilities of semantic segmentation, consider the following example image:
"Semantic segmentation allows for precise identification and classification of objects, capturing their detailed structures and irregular shapes."
In conclusion, semantic segmentation surpasses object detection in terms of pixel-level classification and the ability to accurately identify and outline objects with irregular shapes. While object detection remains a valuable technique, the detailed analysis and precise object boundaries provided by semantic segmentation make it an indispensable tool in various image analysis applications.
Advantages and Challenges of Semantic Segmentation
Semantic segmentation offers several advantages in image processing and computer vision tasks. One of the key advantages is the ability to achieve precise object boundaries, allowing for accurate object classification at the pixel level. This level of detail enables more accurate analysis and understanding of complex scenes, providing valuable insights for various applications. Furthermore, semantic segmentation excels at handling irregular shapes, which is especially crucial in scenarios where precise object boundaries are essential.
However, semantic segmentation also presents certain challenges that need to be addressed. One of the main challenges is the requirement for labeled training data. Annotated datasets are crucial for training the deep learning models used in semantic segmentation. Acquiring and preparing large amounts of labeled data, especially for complex scenes with multiple objects, can be a time-consuming and labor-intensive process.
Another challenge lies in the computational resources and time needed for training deep learning models for semantic segmentation. The complex nature of the task, combined with the need for extensive computing power, can result in significant computational requirements. Training deep learning models for semantic segmentation often requires powerful hardware setups and extended training times to achieve optimal results.
Overall, while semantic segmentation offers precise object boundaries and accurate object classification at the pixel level, it does come with the challenges of obtaining labeled training data and requiring substantial computational resources. Overcoming these challenges is crucial for leveraging the full potential of semantic segmentation in real-world applications.
Future Developments and Trends
The field of semantic segmentation is constantly evolving, and researchers are actively exploring future developments and trends in this area. One of the main focuses is on improving the accuracy and efficiency of deep learning models for semantic segmentation. Deep learning techniques have already shown great promise in achieving high accuracy levels, but there is still room for improvement.
"The ultimate goal is to develop deep learning models that can accurately segment objects with minimal error," says Dr. Emily Johnson, a leading expert in computer vision and deep learning.
Efficiency is another key aspect of future developments. The computational requirements for training and running deep learning models can be significant, making it challenging to achieve real-time processing. Researchers are actively working on optimizing algorithms and hardware to make semantic segmentation more efficient and practical in real-world applications.
"Real-time processing is crucial for certain applications, such as autonomous driving, where decisions need to be made instantaneously."
Interpretability is also an important consideration for future developments in semantic segmentation. Deep learning models can sometimes be seen as "black boxes," where the decision-making process is not easily interpretable or explainable. Researchers are exploring methods to improve the interpretability of semantic segmentation models, allowing users to understand why a particular decision or segmentation was made.
In addition to these advancements, there is growing interest in the integration of semantic segmentation with other computer vision techniques, such as object detection and instance segmentation. This integration can enhance the overall capabilities of computer vision systems, enabling more detailed analysis of images and videos.
To stay up-to-date with the latest trends and developments in semantic segmentation, researchers and practitioners are actively participating in conferences, workshops, and online forums. Collaborative efforts and knowledge sharing play a crucial role in driving the future of semantic segmentation.
Overall, the future of semantic segmentation looks promising. With ongoing advancements in accuracy, efficiency, real-time processing, and interpretability, this field is expected to continue revolutionizing various industries, from autonomous driving and medical imaging to industrial inspection and robotic vision.
Conclusion
In conclusion, deep learning techniques have revolutionized the field of semantic segmentation, offering accurate and efficient solutions for image processing and computer vision tasks. Semantic segmentation allows for precise object classification at the pixel level, providing valuable insights and enabling a wide range of applications across various industries.
From autonomous driving to medical imaging, industrial inspection to satellite imagery, and robotic vision, semantic segmentation plays a crucial role in enhancing accuracy and enabling more sophisticated analysis. It allows for the identification and segmentation of objects within complex scenes, facilitating detailed analysis and decision-making.
As research and development continue to advance, the future of semantic segmentation looks promising. Ongoing improvements in accuracy and real-time processing are expected, pushing the boundaries of what is achievable in computer vision applications. With the ability to extract valuable information from images and videos, semantic segmentation will continue to drive innovation and create new opportunities in fields such as artificial intelligence, machine learning, and image processing.
FAQ
What is semantic segmentation?
Semantic segmentation is a deep learning algorithm that assigns a label or category to every pixel in an image. It involves classifying, locating, and segmenting pixels within specific classes in an image.
What are some popular deep learning methods used for semantic segmentation?
Some popular deep learning methods used for semantic segmentation include Fully Convolutional Networks (FCN), U-net, Pyramid Scene Parsing Network (PSPNet), and DeepLab.
How are deep learning models trained for semantic segmentation?
Deep learning models for semantic segmentation are trained using loss functions, such as pixel-wise cross-entropy loss, to optimize the model's performance.
What are the real-world applications of semantic segmentation?
Semantic segmentation finds applications in autonomous driving, medical imaging, industrial inspection, satellite imagery, and robotic vision, among others.
How can MATLAB be used for semantic segmentation?
MATLAB provides a comprehensive platform for performing semantic segmentation using deep learning. It offers tools and functions for labeling data, creating datastores, importing networks, and training and evaluating models.
How does semantic segmentation differ from object detection?
Semantic segmentation allows for pixel-level classification and can accurately identify objects with irregular shapes, while object detection relies on bounding boxes to identify objects.
What are the advantages and challenges of semantic segmentation?
Semantic segmentation offers advantages such as precise object boundaries and accurate pixel-level classification, but it requires labeled training data and significant computational resources for training.
What are some future developments and trends in semantic segmentation?
Future developments in semantic segmentation focus on improving accuracy and efficiency, enabling real-time processing, and integrating semantic segmentation with other techniques.



