
Data Annotation: Everything You Need to Know for Successful AI Projects

Data annotation is the process of labeling, structuring, or organizing raw data to make it understandable to artificial intelligence and machine learning algorithms. Simply put, people or tools add information to data, and then an AI model learns to interpret it correctly. Properly labeled data is a key element in training AI models. The annotation quality affects the accuracy and reliability of the AI model. If the data is not appropriately annotated, the AI model will learn the wrong patterns, leading to poor performance and errors.
“Garbage in, garbage out” is a key caveat for AI developers.
Choosing the proper annotation tools is equally essential for the data to be correctly labeled. The market for analytical tools for annotation in 2025 is estimated at $2.32 billion, with a forecast growth to $9.78 billion by 2030. Using advanced tools in the annotation process will allow us to speed up the work on the project, increase the accuracy of the annotation, and ensure a unified approach of the annotators to the process.
TL;DR
- Properly labeled data is a key element in training AI models.
- Image annotation remains a leading development direction for now.
- Healthcare, autonomous driving, automotive, retail, and finance are the largest data annotation customers in Q3 2025.
- Focusing on hybrid solutions with automation + expert verification.

Types of Annotation and Application Areas
Annotated data is used in many areas, and each requires a different approach and type of annotation; other types of annotation train AI models to perform various and specific tasks correctly.
Image Annotation
Image annotation is the process of labeling, tagging, or classifying images to train computer vision models. It is essential for developing artificial intelligence that can "see" and "understand" the visual world. The image annotation segment held an estimated 36.3% share of the data annotation tools market in 2024 and is currently the leading growth direction.
Common types of image annotation
- Bounding Boxes. It is one of the most popular methods, where an object is outlined with a rectangle.
- Polygon Annotation. An object is marked with a polygonal line that exactly repeats its shape.
- Semantic Segmentation. Each pixel of the image is labeled according to a class.
- Instance Segmentation. Each object of the same class is individually labeled.
- Keypoint Annotation. Annotate points on an object.
- 3D Cuboids. Annotate objects with 3D rectangles.
- Line & Polyline Annotation. Annotate with lines or curves.



Text annotation
Text annotation is the process of labeling and annotating text data so that artificial intelligence algorithms can understand, classify, and analyze it. AI could not understand what words, sentences, or context mean without text annotation, so it is used as a "training guide" for models. In 2024, the text data annotation tools segment accounted for a larger market revenue, 36.1% of the global tools market.
Common types of text annotation
- Named Entity Recognition. Identifies key entities in text: people, organizations, dates, locations, etc.
- Sentiment Annotation. Indicates the emotional coloring of text: positive, negative, neutral.
- Text Classification. Assigns categories or themes to text.
- Intent Annotation. Determines the user's intent.
- Part-of-Speech Tagging. Markup of parts of speech, where each word receives a grammatical tag: noun, verb, adjective, etc.
- Coreference Annotation. Determines when different words or phrases refer to the same object.
- Semantic Annotation. Indicates relationships between entities in the text.
- Aspect-Based Sentiment Annotation. Analyzes sentiment based on individual aspects or characteristics of an object.



Video Annotation
Video annotation is the process of labeling and annotating objects, events, or actions in a video so that artificial intelligence algorithms can recognize, analyze, and predict them. Without it, artificial intelligence algorithms cannot correctly recognize dynamic scenes, track object motion, or explore events over time.
Common types of video annotation
- Video Object Detection. Labeling objects with rectangular frames in each frame to track them in motion.
- Video Segmentation. Highlighting object boundaries pixel by pixel in each frame so the model can recognize their shape.
- Video Keypoint Annotation. Labeling specific points on objects to analyze movements and poses.
- Activity Recognition. Labeling time intervals in a video to describe events or actions that occur.
Video Annotation
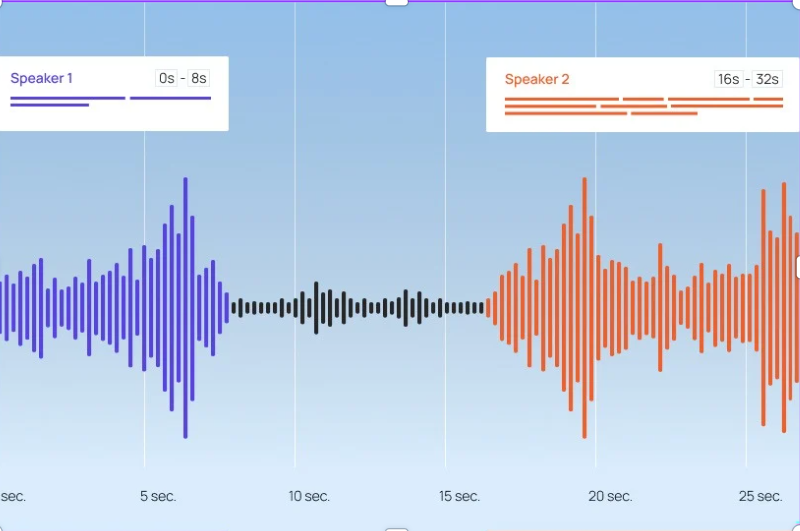
Audio Annotation
Audio annotation adds information or tags to audio files so that a computer system can interpret them correctly.
Common types of audio annotation
- Speech-to-Text. Converting speech to text with time codes and pauses.
- Speaker Diarization. Identifying who is speaking at each moment in a recording.
- Sound Event. Labeling individual sounds or noises in a recording.
- Emotion annotation. Identifying the emotional state of a voice.
- Phonetic annotation. Labeling phonemes, stress, and intonation.
- Noise annotation. Labeling noise or poor quality of a recording.
3D data annotation
3D data annotation is labeling 3D data for training artificial intelligence models. Such data comes from LiDAR, stereo cameras, sensors, or 3D scanners.
Common types of 3D data annotation
- Bounding boxes. Constrain objects in space with x, y, and z coordinates and dimensions along all axes.
- Point cloud annotation. Each point in a 3D cloud is labeled with a class or object.
- Semantic segmentation. The allocation of each pixel or point in the cloud to classes.
- Instance segmentation. The allocation of individual instances of objects in 3D.
- Cuboids / Polygons / Meshes. Precise framing of complex objects in three-dimensional space.
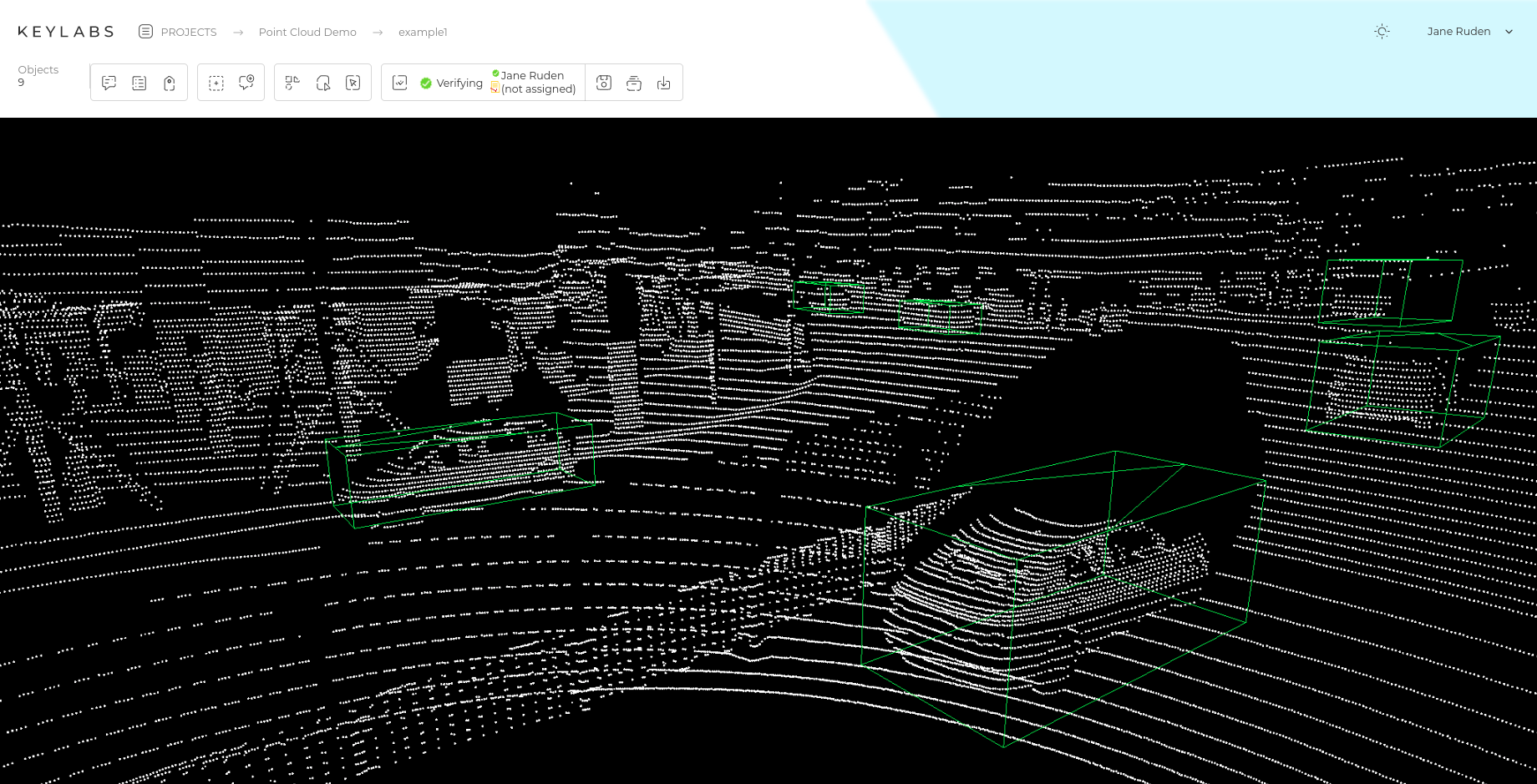
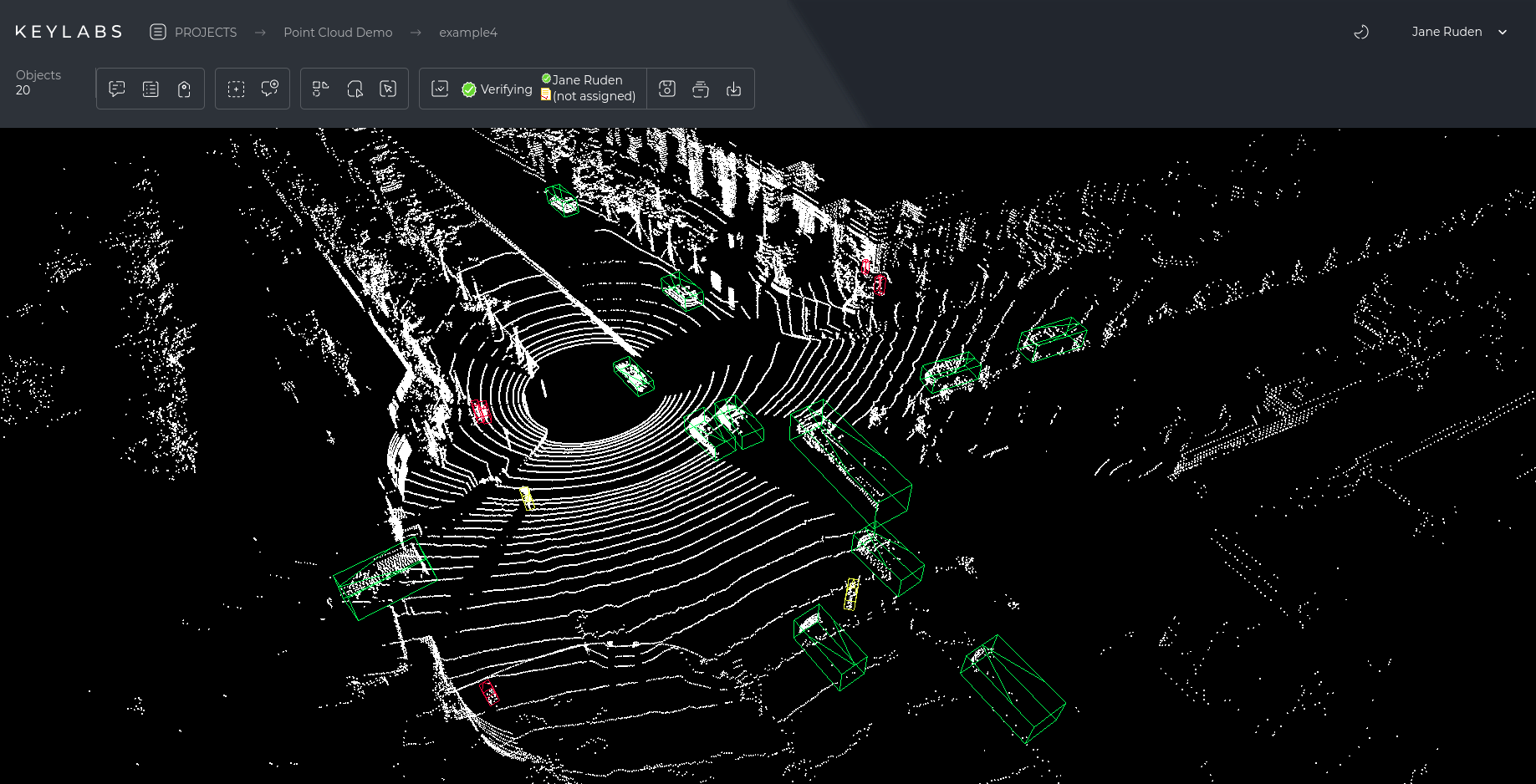

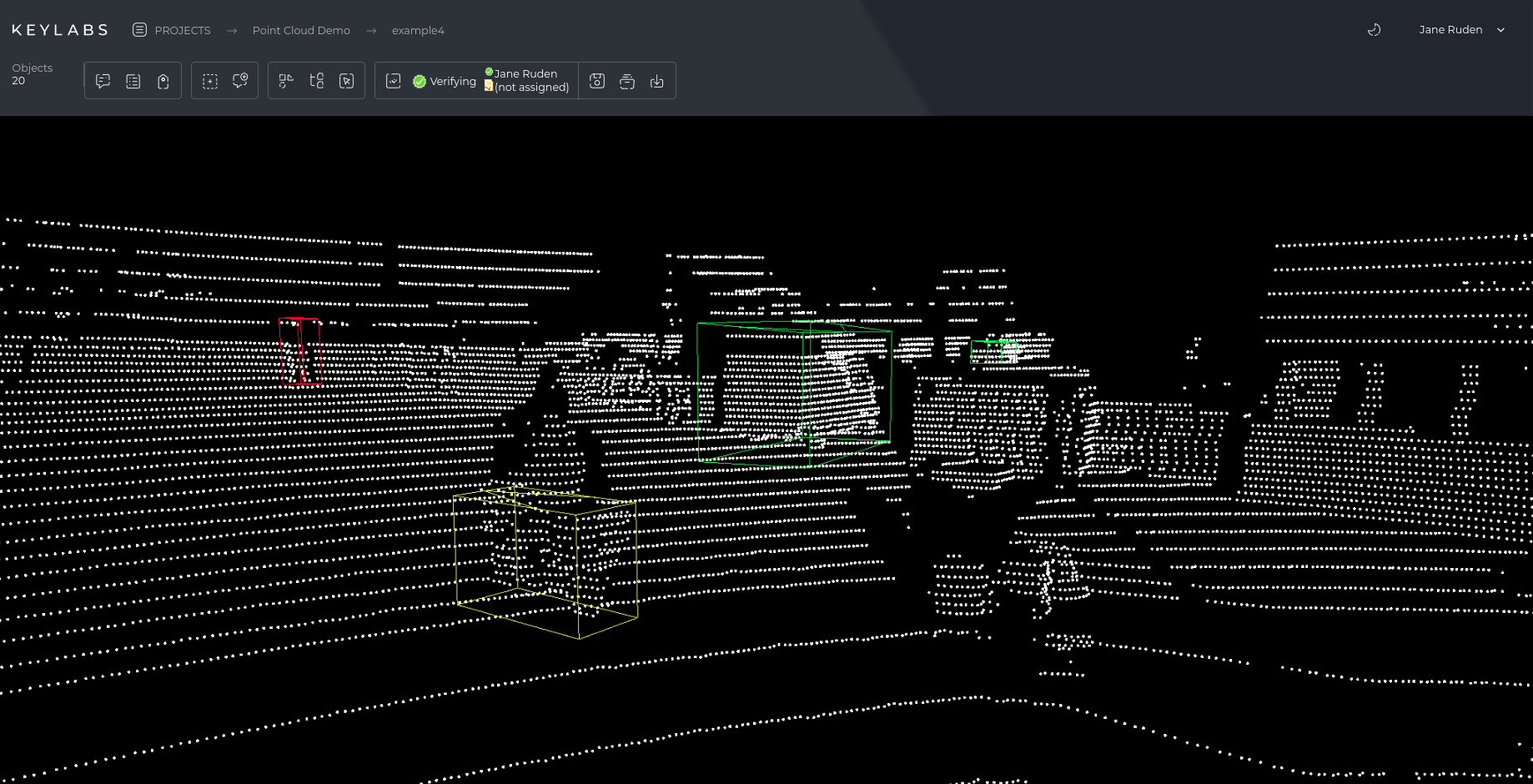
The Keylabs platform supports all the above annotation types, making it convenient for projects in autonomous transportation, medicine, security, agriculture, and many other industries. Keylabs combines an intuitive interface with automation tools.
For example, the function of automatic object marking or interpolation between frames in video reduces the amount of manual work of the annotator. The platform allows you to organize full-fledged team collaboration: manage users, assign roles, track progress, and generate reports. The flexibility of integrations with machine learning models and the ability to export results in various formats make it compatible with most ML platforms.
3D data annotation
Data Validation
Data Validation is the quality control of an annotation that has already been made.
The main aspects to look for are:
- whether the objects / categories are correctly marked;
- whether there are any errors, omissions or inconsistencies;
- whether the work complies with the instructions.

Types of data validation
Automatic validation is data verification using software tools without human intervention. After annotation, a verification script is launched, it checks the data according to established rules. Errors are logged and corrected by annotators or the system.
Manual validation is when the quality of the markup is checked by an annotator, and not only automatic scripts. Automatic scripts detect only technical errors, to understand their meaning, manual verification is used. This gives confidence that the data is annotated correctly from the point of view of the task.
Semi-automatic validation is a combined approach, when part of the markup is checked automatically, and part by an annotator. This approach preserves the speed of automation and the accuracy of a human.

Data Verification
Data Verification is the process of checking the authenticity and accuracy of data to ensure that it matches the original source or reality. The goal of this process is to detect errors or subjective deviations of the annotator in order to increase consistency between annotators.
Verification methods
Manual verification by an expert is when an annotator reviews the markup and assesses its accuracy. This is a reliable way to ensure that the markup corresponds to reality and the task.
Cross-validation is when multiple annotators mark up the same data independently of each other. This method helps to detect subjective errors and increase consistency.
Random verification is when a portion of the dataset is checked randomly. This saves time and gives an idea of the overall quality of the markup.
Automated scripts are programs that check certain aspects of the markup without human intervention. This helps to quickly find errors, but cannot assess semantic accuracy.

Who uses these applications?
Strategies for building a data annotation process
For AI models to perform tasks correctly in the real world, it is not only the quality of the annotation and data validation that matters. The data annotation process plays an important role, and the right choice can determine whether the project will be fast and with high-quality results or slow with many errors, leading to more costs and time spent on rework.
In-house
Data is marked up within the company by employees who understand the product or subject area well.
Outsourcing
This is the transfer of labeling and data preparation tasks to external companies instead of performing them in-house.
Hybrid
Combines internal company resources and external outsourcing for data annotation.
AI + Human in the Loop
This is a collaborative approach where AI and humans work in a loop to ensure quality, accuracy, and control of results. The AI Data Annotation Service Market Insights 2025 report indicates that the data annotation service sectors, including human lifecycle processes, will be valued at USD 4.2-7.2 billion in 2025 and are projected to grow by 2030 with a CAGR of ≈ 8.5-16.5%.
Best practices
Let's consider the best practices for optimizing the data annotation process. A properly organized process will help save time and money by optimally distributing resources.
Quality control
It is a multi-level system for checking labeled data for accuracy and compliance with standards.
How it works:
- First level (Initial Annotation). An annotator or AI marks up the data according to instructions.
- Second level (Review). Another annotator or QA specialist checks the work for errors, omissions, or inconsistencies.
- Third level (Final Verification). A manager or expert checks important data for compliance with standards, domain expertise, or regulatory requirements.
What does it provide?
- Several levels of verification detect and correct errors at the initial stage, which reduces the number of inaccuracies in the final data.
- Maintaining markup consistency is essential because the standards are applied equally at all levels and for all annotators.
- Improves the process and AI learning through feedback and correction.
- Provides organizational control over the work of teams, and evenly distributes responsibility and ensures standardized quality at all stages.
Active learning
This is an approach where the AI system itself determines which data examples need to be manually labeled. Instead of annotating the entire data set, the system focuses on important or complex cases.
How it works:
- AI makes initial predictions on unknown data.
- Ambiguous or complex examples are identified where the model has low confidence.
- These examples are sent for manual annotation by annotators.
- After verification, the data is returned to the AI model for further training.
- The cycle is repeated until the accuracy of the AI model becomes high.
Advantages:
- Less annotation costs, because instead of labeling all the data, people work only with valuable and complex examples.
- Faster AI training. The model receives examples that help it improve its results.
- Data quality. The system selects data where it has uncertainty, and these cases strengthen “weak points”.
- Optimal allocation of human resources. Experts spend time on data where their participation is needed.
- Flexibility and scalability. The method is effective for small and large projects.
- Fast iteration cycle. The model quickly reaches the required level of accuracy because it “learns from its mistakes.”
Synthetic Data
It is artificially generated data, imitating the characteristics of real data but not tied to specific people or real objects.
How synthetic data is created:
- Generation using AI/ML models.
- 3D traffic simulations for training autonomous cars.
- Synthetic medical images are used to create X-rays or MRIs with simulated pathologies.
- Synthetic text or speech for NLP or voice recognition systems.
Why is it needed:
- Security and privacy. There is no risk of personal data leakage.
- Accessibility. It is easy to obtain a large amount of data in areas where real data is rare or expensive.
- Data balance. More examples of rare cases can be specially generated.
- Flexibility. Data is created for specific scenarios that are lacking in reality.
Feedback loops
This is the process of feeding data from users or annotators back into the system to improve the quality of annotations and train AI.
How it works:
- AI or a human annotates the data.
- The result is checked by QA, experts, or automatic metrics.
- Errors and inaccuracies are captured and returned as feedback.
- The model or team of annotators learns from these corrections.
- The next iteration takes into account the experience gained.
Why is this needed:
- Each new iteration makes the markup and model more accurate.
- The system adapts to new data, conditions, or domain specifics.
- The team of annotators receives clear insights into typical errors.
- Corrections are integrated back into the model to improve its accuracy.
Checklist for ML Teams
Let's look at three key aspects that will help you choose a vendor, complete the annotation process, and make it part of your ML pipeline.
How to check data readiness
What to consider when choosing an annotation provider
- Annotation quality. Accuracy and consistency of annotations, examples of previous projects or demo data, and what quality control methods they use.
- Experience and expertise. Do they work with your type of data? Are there domain experts?
- Technologies and tools. Support or availability of modern platforms and annotation tools, process automation, and integration with ML pipeline.
- Scalability. Ability to quickly increase the volume of work without losing quality, availability of your own team or crowdsourcing resources.
- Security and privacy. Compliance with GDPR/HIPAA rules, data encryption, and NDA.
- Price and payment model. Cost per unit of annotation, transparency of calculations, and possibility of a test project before a large-scale order.
- Support and communication. Speed of response, flexibility in changing requirements, and availability of a project manager.
- Reputation and reviews. Reviews of other clients, cases, and market rating.
How to integrate annotation into a pipeline
To get a continuous loop:
Collection → Annotation → Verification → Training → Validation → Selection of new data for annotation
You need to think about integration at all these stages. To do this, follow the step-by-step instructions below:
FAQ
What is the difference between data annotation and data labeling?
Data labeling is the process of assigning specific labels or categories to data, while Data annotation includes not only labels but also additional information (bounding boxes, segmentation, transcription, attributes).
Is it possible to fully automate the data annotation process?
It is not yet possible to fully automate the data annotation process; complex and contextual tasks require human judgment. The best approach today is a hybrid. Automated tools perform the initial annotation, and humans check and correct errors.
Which areas benefit most from high-quality data annotation?
Medicine, autonomous transportation systems, and financial services benefit the most, where data accuracy affects safety and performance. There is also a significant impact in retail, agritech, and security, where annotation ensures the correct operation of recognition and prediction systems.
How do you know when your data is ready for training?
Data is ready for training when it is complete, clean, properly annotated, and stored in a format compatible with the model.
How do you control quality at scale?
Control through multi-level checks, automated scripts to detect technical errors, and selective expert audits. Additionally, they track consistency metrics between annotators and active learning to quickly find and fix problematic data.
