
Best Datasets for Training Semantic Segmentation Models

Semantic segmentation plays a crucial role in computer vision applications, enabling the precise identification and labeling of objects within an image. To train highly accurate and effective semantic segmentation models, it is essential to have access to high-quality training datasets. These datasets not only provide the necessary labeled examples for model training but also contribute to the development and advancement of deep learning algorithms.
In this article, we will explore some of the best datasets available for training semantic segmentation models, covering a range of applications and domains. Whether you are working on autonomous driving, object detection, or image analysis tasks, these datasets offer valuable resources for training your models.
Key Takeaways:
- Training datasets are crucial for developing accurate and robust semantic segmentation models.
- High-quality datasets contribute to the advancement of deep learning algorithms.
- Different datasets cater to diverse applications, such as autonomous driving and object detection.
- Consider factors like dataset size, task complexity, and available computing resources when selecting a dataset.
- Data augmentation techniques and hyperparameter tuning can optimize model performance.

Image Segmentation Techniques and Architectures
Image segmentation is a fundamental task in computer vision that involves dividing an image into distinct regions. To achieve accurate and reliable segmentation, advanced techniques and architectures are employed. This section explores some of the key techniques and architectures used for image segmentation, highlighting the importance of annotated training datasets in this process.
Encoder-Decoder Architecture
The most common architecture for image segmentation is the encoder-decoder architecture. This architecture consists of two main components, the encoder and the decoder. The role of the encoder is to capture high-level features from the input image, while the decoder generates the pixel-wise segmentation mask.
One popular encoder-decoder architecture is U-Net, which has gained significant popularity in the computer vision community. U-Net follows a U-shaped architecture, with a contracting path for capturing context and a symmetric expansive path for precise localization. This architecture enables effective feature extraction and accurate pixel-level segmentation.
Other Architectures
In addition to U-Net, several other architectures have been developed for image segmentation. These architectures aim to improve the performance and efficiency of segmentation models. Some notable architectures include:
- Joint Pyramid Upsampling (JPU) module: This architecture incorporates multiple branches with different receptive fields, allowing for multi-scale feature fusion and leveraging context information effectively.
- Gated Shape CNNs: These networks incorporate spatial and channel-wise attention mechanisms to enhance the representation and context of the segmentation task.
- DeepLab with atrous convolution: This architecture utilizes atrous convolution, also known as dilated convolution, to capture multi-scale contextual information without increasing the model's parameters.
These architectures have shown promising results in various computer vision tasks, including image segmentation. However, to train and evaluate these architectures effectively, annotated image datasets are essential.
Importance of Annotated Image Datasets
To train image segmentation models, annotated image datasets are crucial. These datasets consist of images paired with pixel-level annotations, which serve as ground truth masks for training and evaluation purposes.
Annotated image datasets provide the necessary training data for the model to learn the boundaries and characteristics of different objects in the image. They enable the model to understand the spatial relationships and context, which are vital for accurate segmentation.
Computer vision datasets, such as COCO (Common Objects in Context) and ImageNet, often provide annotated images suitable for training image segmentation models. These datasets cover a wide range of object categories and scenes, making them valuable resources for developing robust segmentation models.
Summary
Image segmentation techniques and architectures play a crucial role in achieving accurate and reliable segmentation results. The encoder-decoder architecture, exemplified by U-Net, is widely used for its effectiveness in feature extraction and precise localization. Other architectures, such as JPU, Gated Shape CNNs, and DeepLab, offer additional advancements in segmentation performance.
To train these architectures effectively, annotated image datasets are essential. These datasets provide valuable training data, enabling models to learn the intricate details and context necessary for accurate segmentation.
Object Detection Datasets for Semantic Segmentation
Object detection is a widely used application of semantic segmentation. It involves identifying and localizing objects in an image through bounding boxes and pixel-wise masks. To train accurate and robust object detection models, access to high-quality labeled datasets is essential. Here are some of the top datasets available for training object detection algorithms:
- COCO Dataset: The COCO dataset is one of the most popular and comprehensive datasets for object detection and segmentation. It contains millions of annotated images across various object categories, making it suitable for training models on a wide range of objects.
- Open Images: The Open Images dataset is a large-scale dataset created by Google. It offers a diverse collection of images with bounding box and segmentation annotations, providing ample training data for object detection tasks.
- PASCAL VOC 2012: The PASCAL VOC 2012 dataset is another widely used dataset for object detection and segmentation. It consists of labeled images from the PASCAL Visual Object Classes challenge, covering multiple object categories.
- Cityscapes: The Cityscapes dataset focuses on urban scenes and is specifically designed for autonomous driving applications. It contains highly detailed annotations for objects such as cars, pedestrians, and bicycles.
These datasets provide a rich source of labeled images for training and evaluating object detection algorithms. Researchers and practitioners can leverage these datasets to build accurate and reliable models for various real-world applications.
Example Table:
| Dataset | Annotations | Object Categories | Image Count |
|---|---|---|---|
| COCO | Bounding Boxes, Segmentations | 80+ | Millions |
| Open Images | Bounding Boxes, Segmentations | 600+ | Millions |
| PASCAL VOC 2012 | Bounding Boxes, Segmentations | 20 | Thousands |
| Cityscapes | Bounding Boxes, Segmentations | 8 | Tens of Thousands |
Note: The table above provides a brief overview of the datasets' key attributes, including the type of annotations, the number of object categories, and the total count of images available for training.
Computer Vision Datasets for Semantic Segmentation
Computer vision datasets play a crucial role in training and evaluating semantic segmentation models. These datasets provide valuable resources for developing and fine-tuning algorithms that can accurately segment and classify objects within images. When it comes to semantic segmentation, computer vision datasets offer diverse training data, enabling models to learn and generalize effectively.
One of the most widely used computer vision datasets for pre-training deep learning models is ImageNet. With millions of labeled images spanning various object classes, ImageNet serves as a rich source of training data for semantic segmentation tasks. By leveraging the diverse range of objects and scenes in this dataset, models can develop a strong understanding of visual patterns, leading to improved segmentation accuracy.

In addition to ImageNet, there are other computer vision datasets that are valuable for training semantic segmentation models.
CIFAR-10: This dataset consists of 60,000 images categorized into 10 classes, making it suitable for training and benchmarking computer vision models, including those for semantic segmentation.
CIFAR-100: Similar to CIFAR-10, CIFAR-100 provides a more challenging task, as it contains 100 classes of images. This dataset offers a higher level of complexity, allowing models to handle a wider range of semantic segmentation tasks.
STL-10: Comprising 10 classes of labeled images, STL-10 is a dataset specifically designed for unsupervised learning tasks, including semantic segmentation. Its versatility makes it suitable for training models that can effectively segment various objects and scenes.
Furthermore, machine learning datasets like MNIST and Fashion-MNIST can also be useful for training and benchmarking semantic segmentation models. Although these datasets were originally intended for image classification tasks, they can still provide valuable training data for models aimed at segmenting specific objects or regions within images.
To summarize, computer vision datasets, such as ImageNet, CIFAR-10, CIFAR-100, STL-10, MNIST, and Fashion-MNIST, encompass diverse object classes and scenes, enabling models to learn and generalize effectively in semantic segmentation tasks. By leveraging these datasets, AI practitioners can train robust models capable of accurately segmenting objects and regions within images.
| Dataset | Description |
|---|---|
| ImageNet | A large-scale dataset with millions of labeled images spanning various object classes, commonly used for pre-training deep learning models. |
| CIFAR-10 | A dataset consisting of 60,000 images categorized into 10 classes, suitable for training and benchmarking computer vision models. |
| CIFAR-100 | A more challenging dataset with 100 classes of images, offering a higher level of complexity for semantic segmentation tasks. |
| STL-10 | A dataset specifically designed for unsupervised learning tasks, including semantic segmentation, with 10 classes of labeled images. |
| MNIST | A dataset originally designed for image classification tasks, containing 70,000 grayscale images of handwritten digits. |
| Fashion-MNIST | A dataset similar to MNIST, but with grayscale images of fashion items, suitable for training and benchmarking segmentation models. |
Open Source Datasets for Semantic Segmentation
Open source datasets offer a wide range of options for training semantic segmentation models. These datasets are freely available and provide high-quality training data for semantic segmentation tasks. Some of the notable open source datasets for semantic segmentation are:
COCO Dataset
The COCO dataset, developed by Microsoft, is widely used for object detection and segmentation. It consists of a large collection of images with annotations for object boundaries and object types. The dataset covers a wide range of object categories, making it suitable for training semantic segmentation models.
Open Images Dataset
The Open Images dataset, created by Google, is another valuable resource for training semantic segmentation models. It offers a vast collection of images with bounding box and segmentation annotations. The dataset includes diverse object categories and provides extensive coverage for training and evaluation purposes.
Cityscapes Dataset
The Cityscapes dataset focuses on urban scenes and provides pixel-level annotations for semantic segmentation. It contains high-resolution images of street scenes from various cities, annotated with detailed semantic labels. The dataset is widely used for autonomous driving applications and urban scene understanding.
IMDB-WIKI Dataset
The IMDB-WIKI dataset is a large-scale dataset that consists of images of celebrities from IMDb and Wikipedia. While it is primarily used for face-related tasks, such as age estimation and gender classification, it can also be utilized for semantic segmentation. The dataset offers a diverse collection of images with annotated facial features.
xView Dataset
The xView dataset is designed for object detection and semantic segmentation in aerial imagery. It includes high-resolution satellite images with annotations for various object classes, such as buildings, roads, and vehicles. The dataset is valuable for applications in remote sensing and disaster response.
These open source datasets provide researchers and developers with a wealth of training data for semantic segmentation. By leveraging these datasets, they can train robust and accurate models for a wide range of applications in computer vision and artificial intelligence.
Specialized Datasets for Semantic Segmentation
In addition to general-purpose datasets, there are specialized datasets specifically designed for semantic segmentation tasks. These datasets offer targeted training data for specific semantic segmentation tasks, enabling better model performance and accuracy in specific application domains. Here are some notable specialized datasets:
Furniture-6k Dataset:
The Furniture-6k dataset focuses on images of furniture, making it ideal for applications in interior design or e-commerce. It provides a diverse collection of furniture images with annotated segmentation masks, allowing models to accurately identify and differentiate various furniture items.
Egyptian Hieroglyphics Dataset:
The Egyptian Hieroglyphics dataset offers a unique collection of images for research in historical linguistics and Egyptology. It provides annotated images of ancient Egyptian hieroglyphics, enabling the development of models that can automatically segment and analyze these intricate symbols.
Racetrack Dataset:
The Racetrack dataset is designed for self-driving car applications. It consists of high-resolution images captured from various racetracks, along with pixel-wise segmentation masks. This dataset allows researchers and developers to train models that can accurately segment the track and identify different elements on the racetrack.
Personal Protective Equipment Dataset:
The Personal Protective Equipment (PPE) dataset is specifically aimed at workplace safety applications. It contains images of workers wearing different types of PPE, such as helmets, goggles, and safety vests. With annotated segmentation masks, models trained on this dataset can accurately identify and segment PPE to ensure compliance with safety regulations.
These specialized datasets provide invaluable resources for researchers and developers working on specific semantic segmentation tasks. By leveraging these datasets, they can train models that are tailored to the unique requirements of their application domains, leading to more accurate and efficient semantic segmentation results.
Government Datasets for Semantic Segmentation
Government agencies play a significant role in providing publicly available datasets that can be utilized for semantic segmentation tasks. These datasets, supported by government funding and collaborations, offer valuable training data for developing robust and accurate semantic segmentation models. By leveraging these government datasets, researchers and developers can enhance their semantic segmentation algorithms and address real-world challenges.
One prominent government dataset in the field of computer vision is the ImageNet dataset. Funded by the US government, this dataset is renowned for its vast collection of labeled images spanning various object categories. ImageNet has been pivotal in advancing the field of semantic segmentation and has become one of the most widely used datasets in computer vision research and development.
Another notable government-funded dataset is the Cityscapes dataset, developed through collaboration between the German and Swiss governments. Cityscapes focuses specifically on urban scenes, making it particularly valuable for semantic segmentation tasks related to autonomous driving applications. With its extensive collection of annotated images, Cityscapes provides rich training data for training and evaluating semantic segmentation models in urban environments.
Additionally, government organizations and initiatives offer specialized datasets in specific domains. For instance, the Argoverse dataset supports research in autonomous vehicle perception and planning. Developed by the Argoverse project, which is focused on advancing self-driving cars, this dataset contains high-resolution sensor data and annotations for various driving scenarios, including semantic segmentation tasks.
Furthermore, Alphabet's self-driving car division, Waymo, contributes to the field of semantic segmentation by providing the Waymo Open dataset. This dataset offers a rich collection of sensor data captured by Waymo's autonomous vehicles, along with high-quality annotations for object detection, tracking, and semantic segmentation. It serves as a valuable resource for training and evaluating advanced semantic segmentation models for autonomous driving applications.
| Dataset | Funding | Domains | Annotations |
|---|---|---|---|
| ImageNet | US government | Various | Object category labels |
| Cityscapes | German and Swiss governments | Urban scenes | Precise pixel-level annotations |
| Argoverse | Argoverse project | Autonomous driving | Sensor data and semantic annotations |
| Waymo Open dataset | Alphabet Inc. | Autonomous driving | Object detection, tracking, and segmentation annotations |
Industrial Datasets for Semantic Segmentation
Industrial datasets play a crucial role in training semantic segmentation models for specific industries. These datasets provide targeted training data for accurate and reliable segmentation models in specialized domains. Two notable industrial datasets are the Cable Damage dataset and the Aquarium dataset.
Cable Damage Dataset
The Cable Damage dataset is specifically designed for infrastructure and energy applications, with a focus on detecting cable damage. It offers a collection of annotated images that can be used to train models for identifying and segmenting cable damage accurately. This dataset enables the development of robust solutions for cable maintenance and inspection in industries that rely heavily on energy and infrastructure systems.
Aquarium Dataset
The Aquarium dataset provides images of fish, making it ideal for applications in aquaculture and fisheries. With semantic segmentation, the dataset allows for precise identification and localization of different fish species. By training models using this dataset, industries can enhance their fish monitoring systems, optimize feeding and breeding strategies, and improve overall productivity and sustainability in aquaculture and fisheries.
These specialized industrial datasets offer valuable training data for semantic segmentation models in specific industries. By leveraging the Cable Damage dataset and the Aquarium dataset, industries can develop accurate and efficient solutions tailored to their respective domains.
Choosing the Right Dataset for Semantic Segmentation
When it comes to semantic segmentation, selecting the appropriate dataset is of utmost importance. Several factors need to be considered to ensure optimal model performance. Let's explore these factors in detail:
Dataset Size
The size of the dataset plays a crucial role in training a semantic segmentation model. Smaller datasets may lead to overfitting, where the model becomes too specialized in recognizing the specific samples in the dataset, but fails to generalize well to unseen data. On the other hand, a larger dataset provides more diverse examples and helps the model to learn a wider range of patterns and variations.
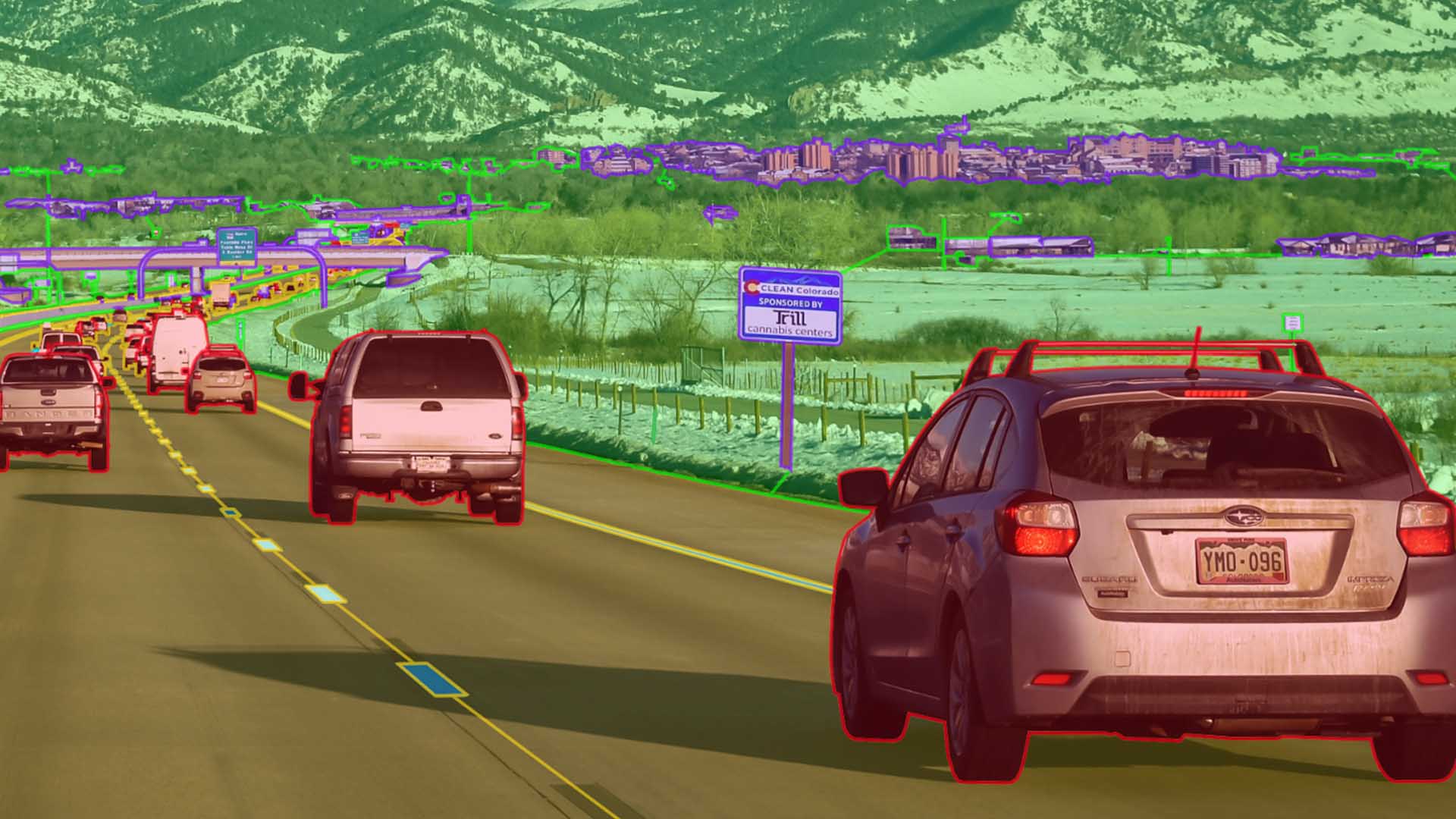
Task Complexity
Different semantic segmentation tasks have varying levels of complexity. Some datasets may contain fine-grained details that require the model to learn intricate patterns and subtle visual cues. On the contrary, other datasets may focus on more straightforward segmentation tasks with fewer complexities. Understanding the complexity of the task at hand allows you to choose a dataset that aligns with your specific requirements.
Computing Resources
Consider the computing resources and infrastructure available for training your segmentation model. More complex datasets with high-resolution images or a large number of classes require more computational power and memory. Ensure that your hardware and resources can handle the computational demands associated with the dataset you choose.
Matching Dataset to Task Requirements
Finally, it is essential to choose a dataset that aligns with the specific requirements of your semantic segmentation task. Consider the domain and application you are working in and select a dataset that closely matches these criteria. This ensures that the model is trained on relevant examples and can generalize well to real-world scenarios.
By carefully considering these factors, you can make an informed decision when choosing the right dataset for your semantic segmentation task. The appropriate dataset will provide the necessary training examples and variations to help your model achieve accurate and reliable results.
Training Models with Semantic Segmentation Datasets
Once a suitable dataset has been chosen, the training process for semantic segmentation models can begin. Training a model involves optimizing its parameters based on the provided dataset, allowing it to learn and make accurate predictions.
The first step in training a semantic segmentation model is to divide the chosen dataset into two sets: a training set and a validation set. The training set is used to train the model, while the validation set is used to evaluate the model's performance and make necessary adjustments.
To train semantic segmentation models, various deep learning frameworks provide tools and APIs that simplify the process. Popular frameworks like TensorFlow and Keras offer functionalities for creating, training, and evaluating segmentation models efficiently.
In order to improve the generalization capability of the model, data augmentation techniques can be applied. Data augmentation involves generating new training samples by applying transformations such as rotation, scaling, and flipping to the original dataset. This increases the diversity of the training data, allowing the model to learn from a broader range of examples.
Additionally, hyperparameter tuning plays a crucial role in optimizing model performance. Hyperparameters are parameters that are set prior to training and affect the learning process, such as learning rate, batch size, and regularization strength. By iteratively adjusting these hyperparameters and evaluating the model's performance on the validation set, the optimal combination of hyperparameters can be found, resulting in improved model accuracy.
Regularization methods can also be employed to prevent overfitting, which occurs when a model becomes too specialized in the training data and fails to generalize well to new examples. Techniques such as L1 or L2 regularization, dropout, and batch normalization can help prevent overfitting and improve the model's ability to generalize to unseen data.
By training semantic segmentation models on high-quality datasets, optimizing hyperparameters, and leveraging data augmentation and regularization techniques, it is possible to achieve accurate and reliable results for a variety of semantic segmentation tasks.
Key Points:
- The training process begins after choosing a suitable dataset for semantic segmentation.
- Divide the dataset into training and validation sets.
- Deep learning frameworks like TensorFlow and Keras provide tools for training semantic segmentation models.
- Data augmentation techniques increase the diversity of training data for better generalization.
- Hyperparameter tuning optimizes model performance.
- Regularization methods prevent overfitting and improve generalization.
Conclusion
The availability of high-quality datasets plays a critical role in training accurate and robust semantic segmentation models. From general-purpose datasets like COCO and ImageNet to specialized datasets for specific tasks, there is a wide range of options to choose from. When selecting a dataset, considerations such as size, task complexity, and available computing resources should be taken into account.
Proper training and evaluation processes, along with data augmentation and hyperparameter tuning, are key to maximizing the performance of semantic segmentation models. By leveraging the right dataset and following best practices in training, these models can achieve accurate and reliable results for various applications.
Overall, semantic segmentation datasets provide the foundation for developing sophisticated computer vision models. As the field advances, the availability of diverse and high-quality datasets will continue to drive innovation and improve the accuracy and reliability of semantic segmentation models.
Summary:
- High-quality datasets are crucial for training accurate and robust semantic segmentation models.
- Various datasets, including general-purpose and specialized ones, are available for semantic segmentation tasks.
- Considerations such as dataset size, task complexity, and computing resources should be taken into account when selecting a dataset.
- Proper training, evaluation, and optimization techniques can lead to optimal model performance.
- Semantic segmentation models, when trained with the right dataset and best practices, can deliver accurate and reliable results for a wide range of applications.
FAQ
What is semantic segmentation?
Semantic segmentation is the process of dividing an image into multiple segments, where each pixel is associated with an object type. It involves marking objects of the same type using one class label.
What is the difference between semantic segmentation and instance segmentation?
In semantic segmentation, objects of the same type are marked using one class label, while instance segmentation assigns separate labels to similar objects.
What are some popular image segmentation techniques and architectures?
Some popular image segmentation techniques and architectures include U-Net, Joint Pyramid Upsampling (JPU) module, Gated Shape CNNs, and DeepLab with atrous convolution. These architectures are commonly used in computer vision and require annotated image datasets for training and evaluation.
What are some datasets available for training object detection models?
Some datasets available for training object detection models include the COCO dataset, Open Images, PASCAL VOC 2012, and Cityscapes. These datasets provide labeled images for training and evaluation of object detection algorithms.
What are some computer vision datasets for training semantic segmentation models?
Some computer vision datasets for training semantic segmentation models include ImageNet, CIFAR-10, CIFAR-100, and STL-10. These datasets cover a wide range of object classes and provide diverse training data for computer vision tasks.
Are there any open source datasets available for semantic segmentation?
Yes, there are several open source datasets available for semantic segmentation, such as the COCO dataset, Open Images, Cityscapes, IMDB-WIKI, and xView. These datasets are freely available and offer high-quality training data for semantic segmentation tasks.
Are there any specialized datasets for specific semantic segmentation tasks?
Yes, there are specialized datasets like the Furniture-6k dataset for interior design or e-commerce, the Egyptian Hieroglyphics dataset for historical linguistics and Egyptology, the Racetrack dataset for self-driving car applications, and the Personal Protective Equipment dataset for workplace safety applications.
Are there any government datasets available for semantic segmentation?
Yes, there are government datasets like the ImageNet dataset, funded by the US government, the Cityscapes dataset, developed by German and Swiss governments, the Argoverse dataset for autonomous vehicle research, and the Waymo Open dataset from Alphabet's self-driving car division.
Are there any industrial datasets for semantic segmentation?
Yes, there are industrial datasets like the Cable Damage dataset for infrastructure and energy applications, and the Aquarium dataset for applications in aquaculture and fisheries.
What should be considered when choosing a dataset for semantic segmentation?
When choosing a dataset for semantic segmentation, factors such as size, task complexity, and available computing resources should be considered to ensure optimal model performance.
How can semantic segmentation models be trained with the available datasets?
Semantic segmentation models can be trained using deep learning frameworks like TensorFlow and Keras. The datasets should be divided into training and validation sets for evaluation. Techniques like data augmentation, hyperparameter tuning, and regularization can be employed to optimize model performance.
Why are high-quality datasets crucial for training semantic segmentation models?
High-quality datasets are crucial for training accurate and robust semantic segmentation models. They provide the necessary training data and annotations for the models to learn and generalize effectively.



