
Semantic Segmentation vs Object Detection: Understanding the Differences
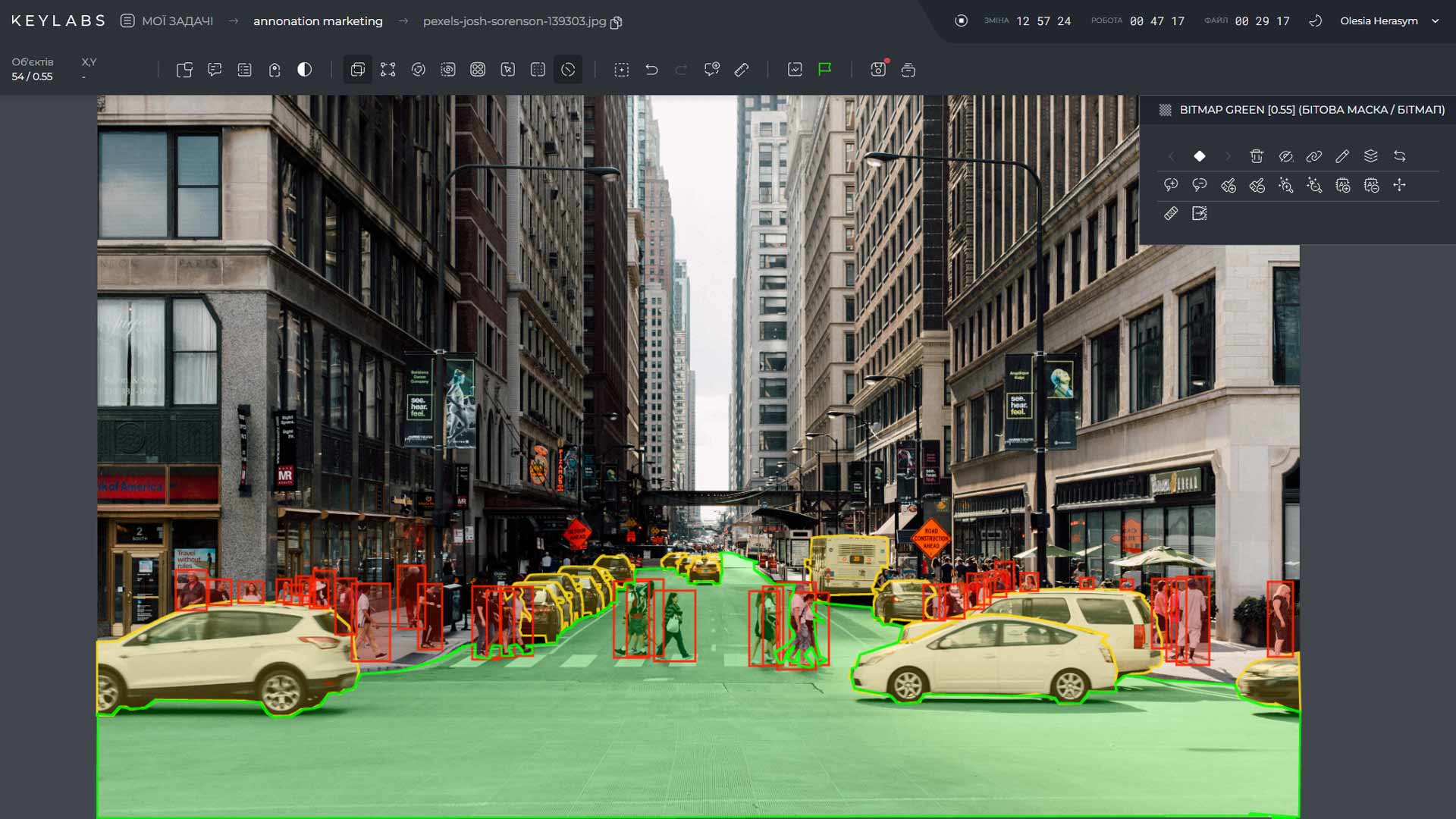
In the field of computer vision, two fundamental tasks that play a crucial role in understanding visual data are semantic segmentation and object detection. While both processes involve analyzing images and identifying specific elements within them, they differ in their approach and applications.
Semantic segmentation involves dividing an image into semantically meaningful regions, assigning class labels to each pixel. Essentially, it provides detailed information about object boundaries and regions of interest. On the other hand, object detection focuses on localizing and classifying specific objects within an image, providing bounding boxes around them.
Understanding the differences between semantic segmentation and object detection is vital for professionals in the AI and machine learning industry. By having a clear understanding of these techniques, they can make informed decisions when developing computer vision projects tailored to their specific requirements.
Key Takeaways
- Semantic segmentation involves assigning class labels to each pixel, providing detailed information about object boundaries and regions.
- Object detection focuses on localizing and classifying specific objects within an image, providing bounding boxes for their locations.
- Understanding the distinctions between semantic segmentation and object detection is crucial for professionals in the AI and machine learning field.
- By leveraging the strengths of these techniques, professionals can make informed decisions in their computer vision projects.
- Both techniques have unique applications and play significant roles in various industries.

Understanding Segmentation
Segmentation is a fundamental process in computer vision that involves breaking down an image or video into distinct and meaningful regions. By dividing the visual content into segments, segmentation enables the identification and differentiation of objects or regions of interest. This process plays a critical role in various domains, including medical image analysis, manufacturing, and robotics.
Semantic Segmentation
Semantic segmentation, a popular technique within the segmentation realm, assigns class labels to each pixel in an image or video. This pixel-level classification allows for a detailed understanding of object boundaries and meaningful regions. By leveraging deep learning algorithms and convolutional neural networks (CNNs), semantic segmentation can accurately identify and label different objects in complex scenes.
Instance Segmentation
Instance segmentation takes segmentation a step further by not only identifying objects but also distinguishing individual instances of those objects. This technique assigns a unique label to each instance within an image, enabling precise object boundary delineation for each occurrence. Instance segmentation can be particularly useful in scenarios where multiple objects of the same class need to be discerned and analyzed separately.
Both semantic segmentation and instance segmentation are indispensable tools in various applications. For example, in medical image analysis, segmentation techniques are utilized for tasks such as tumor detection and organ segmentation. In manufacturing, segmentation is employed to identify defects or anomalies in products. In robotics, segmentation helps localize objects and facilitate object manipulation.
Overall, segmentation provides a foundation for understanding the composition and structure of visual data, enabling the segmentation of images and videos into meaningful regions and object boundaries.
Exploring Object Detection
Object detection plays a critical role in computer vision by localizing and classifying objects within images or videos. Its primary objective is to identify specific objects of interest and provide their bounding boxes. This allows machines to precisely locate and recognize objects, enabling a wide range of applications in various fields such as video surveillance, agriculture, and retail analytics.
Object detection algorithms employ a combination of techniques to accomplish their tasks effectively. They utilize Region Proposal Networks (RPNs) to generate potential object proposals. These proposals are then analyzed by feature extraction networks, which extract relevant features to accurately classify and localize objects within the image or video. Object classification networks are responsible for assigning class labels to the identified objects.
By leveraging these components, object detection algorithms provide crucial information about the location and class of objects, facilitating robust analysis and decision-making. Whether it is identifying objects in a video stream for surveillance purposes or detecting and tracking crops in precision agriculture, object detection proves to be a fundamental tool in extracting valuable insights from visual data.
To better understand the significance of object detection, consider the following practical examples:
- Video Surveillance: Object detection enables accurate identification and tracking of objects, aiding in surveillance and security applications. Systems can detect and flag suspicious activities, identify vehicles or individuals of interest, and monitor restricted areas.
- Agriculture: In precision agriculture, object detection helps monitor and manage crops effectively. By localizing objects like plants, fruits, or pests, farmers can gather data on crop health, optimize irrigation and fertilizer usage, and detect anomalies.
- Retail Analytics: Object detection finds use in retail environments for applications like customer behavior analysis and inventory management. By detecting and tracking objects such as products or customers, retailers can gain insights into shopping patterns, optimize store layouts, and alleviate stockouts.
Object detection, with its ability to localize objects and provide bounding boxes, plays a crucial role in extracting valuable insights from visual data. It is a foundational technique in computer vision, enabling a wide range of applications across multiple industries.
Deep Dive into Classification
Classification is a fundamental task in computer vision that involves assigning labels or categories to images or specific regions. Traditional classification methods relied on handcrafted features and machine learning algorithms. However, with the advent of deep learning techniques, particularly Convolutional Neural Networks (CNNs), image classification has been revolutionized.
CNNs have proven to be highly effective in extracting meaningful features from images, enabling accurate classification.
Popular classification architectures, such as AlexNet, VGGNet, and ResNet, have achieved remarkable performance on various benchmark datasets. These architectures are known for their deep layer structures, allowing them to capture complex patterns and relationships in images.
Classification plays a crucial role in several important applications in computer vision.
Image tagging relies on classification techniques to assign relevant labels to images, enabling efficient organization and retrieval of visual content. Face recognition systems utilize classification algorithms to identify individuals based on their unique facial features. In the field of medical imaging, classification is used for disease diagnosis, extracting vital information from medical scans for accurate detection and treatment planning.
The Power of Convolutional Neural Networks (CNNs)
CNNs are the backbone of modern image classification algorithms. These deep learning networks learn hierarchical representations of images by leveraging convolutional layers, which capture local spatial patterns, and pooling layers, which reduce the spatial dimensionality of the features.
CNNs excel at automatically learning meaningful and discriminative features directly from raw pixel values, eliminating the need for manual feature engineering.
Image Labeling with Classification
Image labeling, a vital aspect of classification, involves assigning descriptive labels to images based on their content. This process enables efficient organization and retrieval of visual data.
By training a CNN-based image classification model on labeled datasets, it can accurately predict the most appropriate labels for new unseen images.
Popular Classification Architectures
| Architecture | Key Features |
|---|---|
| AlexNet | Introduced deeper network architectures, popularizing the use of Convolutional Neural Networks for image classification. |
| VGGNet | Known for its simplicity and use of small convolutional filters, achieving high performance on image classification tasks. |
| ResNet | Revolutionized image classification with residual connections, enabling deeper networks to be trained without degradation in performance. |
Comparative Analysis and Use Cases
When it comes to computer vision tasks, it's essential to understand the distinctions between segmentation, object detection, and classification. By comparing these techniques, we can gain valuable insights and determine their ideal applications.
Segmentation: Fine-Grained Information and Defect Detection
Segmentation is a powerful technique that excels in providing fine-grained information about object boundaries and regions. It goes beyond simple object detection and can precisely identify the extent of objects within an image. This level of detail makes segmentation particularly suitable for tasks like medical image analysis and defect detection in manufacturing processes. For example, in medical imaging, segmentation can help identify tumors, while in manufacturing, it can aid in identifying and locating defects in products.
Object Detection: Locating Specific Objects
Object detection focuses on identifying specific objects within an image and accurately localizing their positions. This technique is particularly prevalent in applications such as video surveillance and agriculture. In video surveillance, object detection enables the identification and tracking of specific objects, enhancing security measures. In agriculture, object detection can be used for tasks like crop monitoring, identifying pests, and ensuring optimal conditions for plant growth.

Classification: Understanding Content and Image Labeling
Classification plays a crucial role in assigning labels to images or specific regions, providing a holistic understanding of their content. This technique finds applications in various tasks, such as image tagging and labeling. For example, classification can be used to automatically assign tags to images based on their content, making it easier to organize and search for specific images within a database. It is also employed in areas like face recognition and disease diagnosis in medical imaging.
"Segmentation, object detection, and classification each offer unique benefits and are suited for different use cases. Segmentation allows for fine-grained analysis of object boundaries, object detection enables the locating of specific objects, and classification provides a comprehensive understanding of image content."
Now, let's take a closer look at a comparative analysis of these three techniques:
| Technique | Key Features | Use Cases |
|---|---|---|
| Segmentation | - Provides fine-grained information about object boundaries and regions - Allows precise defect detection in manufacturing - Enables accurate tumor identification in medical imaging | - Medical image analysis - Defect detection in manufacturing processes |
| Object Detection | - Identifies specific objects and their locations - Utilizes bounding boxes for precise object localization - Enables video surveillance and security monitoring - Aids in agriculture for crop monitoring and pest detection | - Video surveillance and security - Agriculture and crop monitoring |
| Classification | - Assigns labels to images or regions - Provides a comprehensive understanding of image content - Enables image tagging and labeling | - Image tagging and labeling - Face recognition - Disease diagnosis in medical imaging |
Understanding the differences between segmentation, object detection, and classification is crucial for professionals working in computer vision. By analyzing their unique features and identifying their use cases, we can make informed decisions about which technique to leverage based on the specific requirements of our projects.
Segmentation vs Detection: When to Choose Each
In the field of computer vision, professionals often face the dilemma of choosing between segmentation and detection techniques for their projects. Understanding the specific characteristics and applications of these approaches is crucial in making the right decision. Segmentation provides fine-grained information about object boundaries and regions, while detection focuses on identifying specific objects and their locations.
Segmentation
Segmentation is the process of dividing an image or video into meaningful regions, allowing for a more detailed analysis of objects. It is particularly beneficial in tasks that require precise knowledge of object boundaries and regions of interest. Some common applications of segmentation include:
- Medical Image Analysis: Segmentation enables the identification of tumors, organs, and abnormalities in medical images, aiding in diagnosis and treatment planning.
- Manufacturing Defect Detection: By segmenting product images, defects and anomalies can be identified more accurately, ensuring quality control in manufacturing processes.
- Robotics Object Localization: Segmentation helps robots perceive and interact with objects in their environment, enhancing their ability to perform complex tasks.
Here's an image that demonstrates the output of a segmentation algorithm:
Detection
Object detection, on the other hand, aims to identify specific objects within an image or video and determine their precise locations. This approach is useful when the task requires recognizing and localizing specific objects rather than obtaining fine-grained information about object boundaries. Detection finds application in various domains, including:
- Video Surveillance: Object detection is crucial in surveillance systems for identifying and tracking people, vehicles, or other objects of interest.
- Agriculture (Crop Monitoring): By detecting and localizing crops, pests, or diseases, farmers can assess the health and performance of their fields more efficiently.
- Retail Analytics: Object detection enables the analysis of customer behavior, product placement, and inventory management, leading to better decision-making in retail environments.
By understanding the distinctions between segmentation and detection, professionals can make informed choices when it comes to selecting the most appropriate approach for their computer vision projects.
Next, we will explore the differences between detection and classification, shedding light on their unique features and use cases.
Detection vs Classification: Differentiating Factors
Detection and classification are two fundamental tasks in computer vision, each serving distinct purposes depending on the application requirements. Understanding the differentiating factors between these two approaches is crucial for professionals in the field.
Detection: Detection not only provides class labels but also offers precise object locations through bounding boxes. This enables a holistic understanding of the environment and allows for contextual interactions. For example, in augmented reality applications, detection is essential for real-time object interaction and manipulation. By accurately localizing objects, detection enables precise and dynamic augmentations in the user's environment.
Classification: On the other hand, classification focuses on assigning labels to images or regions, providing a high-level understanding of their content. It offers a faster and more efficient solution, particularly in scenarios where fine-grained object information is not necessary. Classification excels in tasks like image tagging and labeling, where the primary objective is to assign descriptive categories to images or regions without the need for precise object localization.
While both approaches play crucial roles in computer vision, the choice between detection and classification depends on the specific requirements of the task at hand. Detection is preferred when accurate object locations are essential, enabling contextual understanding and interaction. Classification, on the other hand, offers a faster and more streamlined solution when detailed object localization is not necessary.
To further illustrate the differences between detection and classification, refer to the simplified table below:
| Factor | Detection | Classification |
|---|---|---|
| Objective | Locating specific objects and providing class labels | Assigning labels to images or regions |
| Output | Bounding boxes with object locations and class labels | Class labels without precise object localization |
| Application | Augmented reality, video surveillance | Image tagging, labeling |
Both detection and classification are powerful tools in computer vision, and their appropriate usage can lead to significant advancements in various fields. By understanding their differentiating factors, professionals can make informed decisions when choosing between the two approaches, aligning their projects with specific requirements and desired outcomes.
Combined Approaches: Fusion of Segmentation, Detection, and Classification
In advanced computer vision applications, the fusion of segmentation, detection, and classification techniques has proven to be a powerful approach. By combining the outputs of these three approaches, machines can leverage the strengths of each to achieve higher accuracy and gain richer insights.
For example, in the context of autonomous driving, the fusion of segmentation, detection, and classification plays a critical role in ensuring safe navigation and intelligent decision-making. Segmentation algorithms can identify drivable areas and other objects on the road, while object detection techniques can precisely pinpoint specific objects like pedestrians and vehicles. Classification then assigns relevant labels to further understand and interpret the environment.
This combined approach enables autonomous vehicles to have a holistic view of the surrounding world, leading to more accurate detection and classification of objects, as well as better contextual understanding.
The fusion of segmentation, detection, and classification is not only relevant to autonomous driving but also finds applications in various fields. For instance, in the field of healthcare, this approach can aid in the identification and analysis of medical images, allowing for more precise diagnosis and treatment planning. Similarly, in retail analytics, combining these techniques can provide deeper insights into customer behavior and product categorization.
By integrating segmentation, detection, and classification, professionals in computer vision can unlock new possibilities and achieve higher accuracy in their applications. This combined approach allows machines to perceive and understand visual data in a more comprehensive manner, paving the way for advancements in fields such as robotics, healthcare, agriculture, and more.

YOLO: A Simple Object Detection Architecture
YOLO (You Only Look Once) is a widely-used object detection architecture that offers fast and efficient detection of objects in images. It has gained popularity due to its simplicity and ability to accurately predict bounding boxes around detected objects.
Unlike traditional object detection architectures that use separate classification and localization stages, YOLO combines both tasks in a single neural network. This eliminates the need for complex computations and significantly speeds up the detection process.
YOLO operates by dividing an image into a grid of cells and predicting bounding boxes for objects that are centrally located within each cell. The architecture predicts six numbers for each box:
- The coordinates of the center
- The width and height
- A confidence factor
- The class of the object
By leveraging these predicted bounding boxes, YOLO effectively localizes and classifies objects in real-time with impressive accuracy.
YOLO's simplicity and speed make it ideal for a wide range of applications, including real-time object detection in videos, autonomous driving systems, surveillance systems, and more. It has also been widely adopted in the research community as a baseline architecture for object detection experiments.
YOLO simplifies object detection by combining classification and localization tasks in a single network, dramatically improving speed and accuracy.
While YOLO is known for its efficiency, it may sacrifice some precision compared to more complex architectures. However, recent iterations such as YOLOv4 and YOLOv5 have further improved performance, pushing the boundaries of real-time object detection.
Evaluating YOLO's Performance
Let's take a look at the performance of YOLO on popular object detection datasets:
| Dataset | YOLO Performance |
|---|---|
| COCO | Mean Average Precision (mAP) of 0.37 |
| PASCAL VOC | mAP of 0.78 |
| Open Images | mAP of 0.41 |
As seen from the table, YOLO achieves competitive performance on various benchmark datasets, making it a reliable choice for many practical applications.
Advantages of YOLO
- Real-time Processing: YOLO's efficiency allows for real-time object detection, making it suitable for scenarios that require immediate response.
- Simplicity: YOLO's straightforward architecture simplifies implementation and reduces computational overhead.
- Single-pass Detection: YOLO processes an entire image in a single forward pass, eliminating the need for sliding windows or complex region proposal networks.
- Object Localization: YOLO provides accurate bounding box predictions, enabling precise object localization in images.
While YOLO excels in speed and simplicity, it may not be the ideal choice for applications that demand extremely high precision or require detection of small objects. In such cases, more complex architectures, such as RetinaNet or SSD, may be better suited.
Next, we will explore RetinaNet, another powerful object detection architecture that offers a different approach to detecting objects.
RetinaNet: A Feature Pyramid Network for Object Detection
RetinaNet is an advanced object detection architecture that leverages feature pyramid networks (FPNs) to improve the accuracy of object detection. FPNs play a crucial role in RetinaNet by extracting and refining location information from intermediate levels in the convolutional backbone.
RetinaNet builds upon the successful YOLO (You Only Look Once) architecture and takes object detection to the next level with its enhanced capabilities. It combines the strengths of high-level semantic features and low-level spatial features to achieve superior object detection performance.
Feature pyramid networks (FPNs) are responsible for capturing multi-scale representations of objects by seamlessly integrating information from different layers of the convolutional backbone. This enables RetinaNet to detect objects of various sizes with greater accuracy.
The integration of FPNs allows RetinaNet to overcome the limitations of traditional object detection architectures that struggle to detect objects at different scales in a single pass. By incorporating FPNs, RetinaNet ensures that both small and large objects are accurately detected, making it a powerful tool for a wide range of object detection applications.
RetinaNet has gained recognition for its exceptional performance, particularly in scenarios that require precise object detection. Its ability to effectively handle objects of different scales and maintain high accuracy makes it a top choice for professionals in the field.
If you're looking for an object detection solution that delivers exceptional accuracy, RetinaNet's feature pyramid networks and its underlying architecture offer a compelling choice.
Sample RetinaNet Architecture:
RetinaNet Architecture - A visual representation of the RetinaNet architecture, showcasing its multi-level feature extraction and object detection capabilities.
Implementations and Considerations
When it comes to object detection implementations, two popular options are YOLO (You Only Look Once) and RetinaNet. These models are widely used in computer vision tasks and have implementations available in popular libraries and repositories like TensorFlow.
Implementations for YOLO and RetinaNet provide code samples and notebooks that make it easier to apply these object detection models on custom datasets.
When choosing an object detection method, several considerations come into play:
- Speed: YOLO is known for its real-time detection capabilities, making it a preferred choice for applications that require quick object detection. On the other hand, RetinaNet sacrifices some speed for improved accuracy, making it suitable for tasks where precision is crucial.
- Accuracy: YOLO offers a good balance between speed and accuracy, achieving competitive performance in detecting objects. RetinaNet, with its feature pyramid network architecture, provides state-of-the-art accuracy and excels in identifying objects at different scales and sizes.
- Application requirements: Consider the specific needs of your application. If real-time object detection is a priority, YOLO may be the better choice. If the task requires accurate detection, especially for smaller objects, RetinaNet can provide better results.
Comparison of YOLO and RetinaNet Implementations
Here is a comparison of the key features and considerations for the YOLO and RetinaNet implementations:
| Feature | YOLO | RetinaNet |
|---|---|---|
| Architecture | Single-stage detector | Two-stage detector with feature pyramid networks (FPNs) |
| Speed | Real-time detection | Slightly slower than YOLO but still efficient |
| Accuracy | Competitive performance | State-of-the-art accuracy |
| Application | Real-time object detection | Precision-based tasks, smaller object detection |
By carefully considering factors such as speed, accuracy, and specific application requirements, you can choose the most suitable object detection implementation, be it YOLO or RetinaNet, for your computer vision project.
Conclusion
Semantic segmentation, object detection, and classification are crucial tasks in the field of computer vision that serve distinct purposes. Semantic segmentation provides detailed information about object boundaries and regions, allowing for fine-grained analysis and understanding of visual data. Object detection, on the other hand, focuses on identifying specific objects within an image or video and accurately localizing their positions using bounding boxes. Classification assigns labels or categories to images or regions, providing a broader understanding of the content at a higher level.
Understanding the differences between semantic segmentation, object detection, and classification is essential for professionals working in computer vision. By comprehending the nuances of these tasks, they can choose the most appropriate approach based on their project requirements, thereby contributing to advancements in various industries. For instance, in medical image analysis, semantic segmentation is valuable for precisely identifying tumor boundaries, object detection assists in locating specific anomalies, and classification aids in diagnosing diseases.
In conclusion, semantic segmentation, object detection, and classification are integral components of computer vision technology. Each task serves a unique purpose in analyzing visual data and has its own set of strengths and applications. By leveraging these techniques appropriately, professionals can unlock new opportunities in fields such as healthcare, manufacturing, surveillance, and more.
FAQ
What is semantic segmentation?
Semantic segmentation is the process of dividing an image or video into meaningful regions to identify and differentiate objects or regions of interest. It assigns class labels to each pixel.
What is object detection?
Object detection involves localizing and classifying objects within an image or video. It aims to identify specific objects of interest and provide their bounding boxes.
What is the difference between segmentation and object detection?
Segmentation focuses on dividing an image into meaningful regions and assigning class labels to each pixel. Object detection, on the other hand, involves localizing and classifying specific objects within an image or video.
How is classification different from segmentation and object detection?
Classification assigns labels or categories to images or specific regions. It provides a holistic understanding of content, while segmentation and object detection provide more detailed information about object boundaries and locations.
When should I choose segmentation over object detection?
Segmentation is ideal for tasks that require fine-grained information about object boundaries and regions. It is suitable for applications such as medical image analysis, manufacturing defect detection, and robotics object localization.
In what scenarios is object detection preferred?
Object detection is suitable for identifying specific objects and their locations. It finds applications in tasks like video surveillance, agriculture for crop monitoring, and retail analytics.
What are the advantages of combining segmentation, detection, and classification?
By combining these approaches, machines can leverage the strengths of each task. For example, in autonomous driving, segmentation identifies drivable areas and objects, object detection identifies specific objects like pedestrians and vehicles, and classification assigns labels for further understanding.
What is YOLO?
YOLO (You Only Look Once) is a simple object detection architecture that quickly predicts bounding boxes around detected objects. It divides an image into a grid of cells and predicts the coordinates, width, height, confidence factor, and class of objects centered in each cell.
What is RetinaNet?
RetinaNet is a more complex object detection architecture that utilizes feature pyramid networks (FPNs). It combines high-level semantic features and low-level spatial features to improve object detection performance.
Are there implementations available for YOLO and RetinaNet?
Yes, there are implementations available for YOLO and RetinaNet in popular libraries and repositories like TensorFlow. These implementations provide code samples and notebooks for applying object detection models on custom datasets.
What factors should I consider when choosing an object detection method?
When choosing an object detection method, it is important to consider factors such as speed, accuracy, and specific application requirements.
How can professionals in computer vision benefit from understanding segmentation, object detection, and classification?
Understanding the distinctions between segmentation, object detection, and classification helps professionals in computer vision select the appropriate approach based on their project requirements, contributing to advancements in various industries.



